


L’aventure que j’ai vécue avec les modules Hailo et Coral TPU M.2 m’a donné envie de tenter l’installation de TensorFlow sur le Raspberry Pi 5. J’avais déjà pas mal cherché sur les blogs et forums de ceux qui m’ont précédé dans cette recherche et j’ai abouti sur l’article d’Allan Alasdair qui m’a aidé dans cette démarche. Je vous présente ici ce qu’Allan a décrit dans son article où il réalise des benchmarks de TensorFlow et du module Coral.
![]()
Plus d’infos sur les niveaux – Cliquez ici
Au sommaire :
- 1 Installer et utiliser TensorFlow sur Raspberry Pi 5
- 2 Comme chien et chat
- 3 Tests avec le radiateur ventilé
- 4 Ma référence
- 5 Conclusion
- 6 Sources
Installer et utiliser TensorFlow sur Raspberry Pi 5
Certaines parties de cet article ont été réalisées avec l’assistance de Copilot
Configuration du Raspberry Pi 5
J’ai utilisé un modèle Raspberry Pi 5 avec 16Go de RAM. Le dernier OS Raspberry Pi OS Bookworm (janvier 2024 : Linux raspberrypi 6.6.62+rpt-rpi-v8 #1 SMP PREEMPT Debian 1:6.6.62-1+rpt1 (2024-11-25) aarch64 GNU/Linux) est installé sur un SSD Raspberry Pi de 256 Go porté par une carte PineBoards AI.
Téléchargez la dernière version de Raspberry Pi OS et configurez votre Raspberry Pi. À moins qu’un écran et un clavier soient connectés au Raspberry Pi, vous devrez au minimum connecter le Raspberry Pi à votre réseau WiFi et activer SSH.
Démarrez le Raspberry Pi puis ouvrez une fenêtre Terminal pour commencer à installer TensorFlow et TensorFlow Lite.
À partir de Raspberry Pi OS Bookworm, les paquets installés via pip doivent être installés dans un environnement virtuel Python. Un environnement virtuel est un conteneur dans lequel vous pouvez installer en toute sécurité des modules tiers afin qu’ils n’interfèrent pas avec votre système Python.
Installation de TensorFlow sur Raspberry Pi 5
L’installation de TensorFlow sur le Raspberry Pi est beaucoup plus compliquée qu’auparavant, car il n’y a plus de paquetage officiel disponible. Cependant, il existe toujours une distribution non officielle, ce qui signifie au moins qu’il n’y aura pas besoin de compiler et installer à partir des sources.
sudo apt install -y libhdf5-dev unzip pkg-config python3-pip cmake make git python-is-python3 wget patchelf
python -m venv –system-site-packages ~/.python-tf
source ~/.python-tf/bin/activate
pip install numpy==1.26.2
pip install keras_applications==1.0.8 –no-deps
pip install keras_preprocessing==1.1.2 –no-deps
pip install h5py==3.10.0
pip install pybind11==2.9.2
pip install packaging
pip install protobuf==3.20.3
pip install six wheel mock gdown
pip install opencv-python
TFVER=2.15.0.post1
PYVER=311
ARCH=python -c 'import platform; print(platform.machine())'
pip install –no-cache-dir https://github.com/PINTO0309/Tensorflow-bin/releases/download/v${TFVER}/tensorflow-${TFVER}-cp${PYVER}-none-linux_${ARCH}.whl
A l’issue de ces opérations vous avez installé TensorFlow.

Vous pouvez quitter l’environnement pyhton-tf
deactivate
Installation de TensorFlow Lite sur Raspberry Pi 5
Il existe toujours un paquetage officiel de TensorFlow Lite pour Raspberry Pi, l’installation est donc beaucoup plus simple que pour TensorFlow en version complète où cette option n’est plus disponible. Tensorflow Lite ne sera pas utilisé dans cet article. Ce sera sans doute pour une prochaine aventure.
python -m venv –system-site-packages ~/.python-tflite
source ~/.python-tflite/bin/activate
pip install opencv-python
pip install tflite-runtime

Tester le fonctionnement de TensorFlow
Apparemment la base de données de test mnist (http://yann.lecun.com/exdb/mnist/) n’est plus accessible. Je me suis tourné vers une autre version de cette base :
https://www.garrickorchard.com/datasets/n-mnist
Cet ensemble de données Neuromorphic-MNIST (N-MNIST) est une version de l’ensemble de données MNIST original basé sur des images. Il se compose des mêmes 60 000 échantillons d’entraînement et 10 000 échantillons de test que l’ensemble de données MNIST original, et est capturé à la même échelle visuelle que l’ensemble de données MNIST original (28×28 pixels). L’ensemble de données N-MNIST a été capturé en montant le capteur ATIS sur une unité motorisée à bascule et en faisant bouger le capteur pendant qu’il visualise les exemples MNIST sur un écran LCD (d’après Orchard, G.; Cohen, G.; Jayawant, A.; and Thakor, N. “Converting Static Image Datasets to Spiking Neuromorphic Datasets Using Saccades », Frontiers in Neuroscience, vol.9, no.437, Oct. 2015 (open access Frontiers link))
Le jeu d’essai MNIST
La base de données MNIST pour Modified ou Mixed National Institute of Standards and Technology, est une base de données de chiffres écrits à la main. C’est un jeu de données très utilisé en apprentissage automatique.

La reconnaissance de l’écriture manuscrite est un problème difficile, et un bon test pour les algorithmes d’apprentissage. La base MNIST est devenue un test standard. Elle regroupe 60000 images d’apprentissage et 10000 images de test, issues d’une base de données antérieure, appelée simplement NIST. Ce sont des images en noir et blanc, normalisées centrées de 28 pixels de côté. (source Wikipedia)
Installer le jeu d’essai
Historiquement, la base est disponible sur le site de Yann Lecun mais le dossier est vide au moment de la réalisation de ce tutoriel. On va récupérer la base sur une autre plateforme qui héberge ce dataset : https://github.com/cvdfoundation/mnist
Vous téléchargerez les images d’entraînement et leurs labels, puis les images de test (t10k) et leurs labels.
Quatre fichiers sont disponibles :
- train-images-idx3-ubyte.gz : images de l’ensemble d’entraînement (9912422 octets)
- train-labels-idx1-ubyte.gz : étiquettes de l’ensemble d’entraînement (28881 octets)
- t10k-images-idx3-ubyte.gz : images de l’ensemble de test (1648877 bytes)
- t10k-labels-idx1-ubyte.gz : étiquettes de l’ensemble de test (4542 octets)La description du format de fichier provient de http://yann.lecun.com/exdb/mnist/. Le format de fichier IDX est un format simple pour les vecteurs et les matrices multidimensionnelles de différents types numériques. Le format de base est le suivant
nombre magique
taille dans la dimension 0
taille dans la dimension 1
taille dans la dimension 2
…..
taille dans la dimension N
données
Le nombre magique est un entier (MSB en premier). Les 2 premiers octets sont toujours 0. Le troisième octet code le type de données :
0x08 : octet non signé
0x09 : octet signé
0x0B : court (2 octets)
0x0C : int (4 octets)
0x0D : float (4 octets)
0x0E : double (8 octets)
Le quatrième octet indique le nombre de dimensions du vecteur/de la matrice : 1 pour les vecteurs, 2 pour les matrices…. Les tailles de chaque dimension sont des entiers de 4 octets (MSB en premier, high endian, comme dans la plupart des processeurs non-Intel). Les données sont stockées comme dans un tableau C, c’est-à-dire que c’est l’index de la dernière dimension qui change le plus rapidement.La base de données MNIST de chiffres manuscrits comporte un ensemble d’apprentissage de 60 000 exemples et un ensemble de test de 10 000 exemples. .

Décompressez ensuite les archives.
gunzip *.gz
Entraîner le réseau de neurones
Activez l’environnement TensorFlow
source ~/.python-tf/bin/activate
Saisissez le programme de test tf_test.py que vous pouvez télécharger ici :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
import tensorflow as tf import numpy as np import os def load_mnist(path, kind='train'): labels_path = os.path.join(path, f'{kind}-labels-idx1-ubyte') images_path = os.path.join(path, f'{kind}-images-idx3-ubyte') with open(labels_path, 'rb') as lbpath: labels = np.frombuffer(lbpath.read(), dtype=np.uint8, offset=8) with open(images_path, 'rb') as imgpath: images = np.frombuffer(imgpath.read(), dtype=np.uint8, offset=16).reshape(len(labels), 28, 28) return images, labels # Chemin vers votre dataset MNIST path = '/home/pi/datasets/mnist' # Chargement des données d'entraînement et de test x_train, y_train = load_mnist(path, kind='train') x_test, y_test = load_mnist(path, kind='t10k') # Normalisation des données x_train, x_test = x_train / 255.0, x_test / 255.0 # Création du modèle model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation='softmax') ]) # Compilation du modèle model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # Entraînement du modèle model.fit(x_train, y_train, epochs=5) # Évaluation du modèle model.evaluate(x_test, y_test) # Sauvegarde du modèle model.save('mnist_model.keras') |
Ce modèle va créer un réseau de neurones simple, puis entraîner le modèle.
- Il charge le dataset MNIST depuis l’emplacement spécifié (/home/pi/datasets/mnist)
- Il normalise les images en divisant par 255 : Les valeurs des pixels des images MNIST vont de 0 à 255 (puisque ce sont des images en niveaux de gris, chaque pixel a une valeur entière entre 0 et 255). Normaliser ces valeurs à une plage commune (0 à 1) permet au modèle d’apprentissage automatique de traiter toutes les entrées sur une échelle uniforme, ce qui peut accélérer et stabiliser l’entraînement.
- Il crée un modèle de réseau de neurones simple avec une couche d’entrée aplatie, une couche dense avec activation ReLU, une couche de dropout pour la régularisation, et une couche de sortie avec activation softmax.
- Il compile le modèle en utilisant l’optimiseur Adam et la fonction de perte sparse_categorical_crossentropy.
- Il entraîne le modèle sur les données d’entraînement pendant 5 époques.
- Il évalue le modèle sur les données de test.
Les résultats du test

On voit que l’apprentissage est efficace :
-
Époque 1 à 5 : Chaque époque correspond à un cycle complet de l’entraînement sur l’ensemble des données d’entraînement. Le modèle a été entraîné pendant 5 époques, et les résultats montrent comment la perte (
loss) et l’exactitude (accuracy) ont évolué pendant chaque époque. Voici ce que vous voyez :- Epoch 1/5 :
loss: 0.2890–accuracy: 0.9161 - Epoch 2/5 :
loss: 0.1416–accuracy: 0.9583 - Epoch 3/5 :
loss: 0.1057–accuracy: 0.9678 - Epoch 4/5 :
loss: 0.0862–accuracy: 0.9734 - Epoch 5/5 :
loss: 0.0742–accuracy: 0.9759
L’exactitude s’améliore à chaque époque, montrant que le modèle apprend bien sur les données d’entraînement.
- Epoch 1/5 :
- Évaluation finale :
-
loss: 0.0717– Cela représente la perte calculée sur les données de test. Une valeur faible indique une bonne performance du modèle en termes de capacité à prédire correctement les labels des images. -
accuracy: 0.9776– Cela signifie que le modèle a une précision de 97,76 % sur les données de test. Cela montre que le modèle est très performant et peut correctement classer la grande majorité des images de test.
-
Alors pourquoi le test indique-t-il 1875 alors que le test comporte 60000 images ?
En fait, les 60,000 images du dataset MNIST sont divisées en petits lots appelés batchs pour faciliter le processus d’entraînement. Chaque epoch (ou époque) représente un balayage à travers toutes les images d’entraînement, et pendant chaque epoch, les images sont divisées en batchs de 32 images.
60,000 images avec 32 images par batch≈1875 batchs
Cela permet au modèle de traiter les données de manière plus efficace et d’optimiser les mises à jour des poids des neurones de manière plus régulière.
De même pour le jeu de test on a 313 * 32 = 10000
Structure du réseau de neurones
Couche d’entrée aplatie (Flatten Layer) :
Cette couche transforme une image 2D de 28×28 pixels en un vecteur 1D de 784 éléments.
Couche dense avec activation ReLU (Dense Layer with ReLU Activation) :
Une couche dense (ou fully connected) avec 128 neurones. Chaque neurone utilise la fonction d’activation ReLU (Rectified Linear Unit) pour introduire de la non-linéarité dans le modèle.
Couche de dropout pour la régularisation (Dropout Layer) :
Cette couche désactive aléatoirement 20% des neurones pendant l’entraînement pour éviter le surapprentissage (overfitting).
Couche de sortie avec activation softmax (Output Layer with Softmax Activation) :
Une couche dense avec 10 neurones correspondant aux 10 classes de chiffres (0-9). La fonction d’activation softmax convertit les valeurs de sortie en probabilités, facilitant ainsi la classification.
Pour en savoir plus
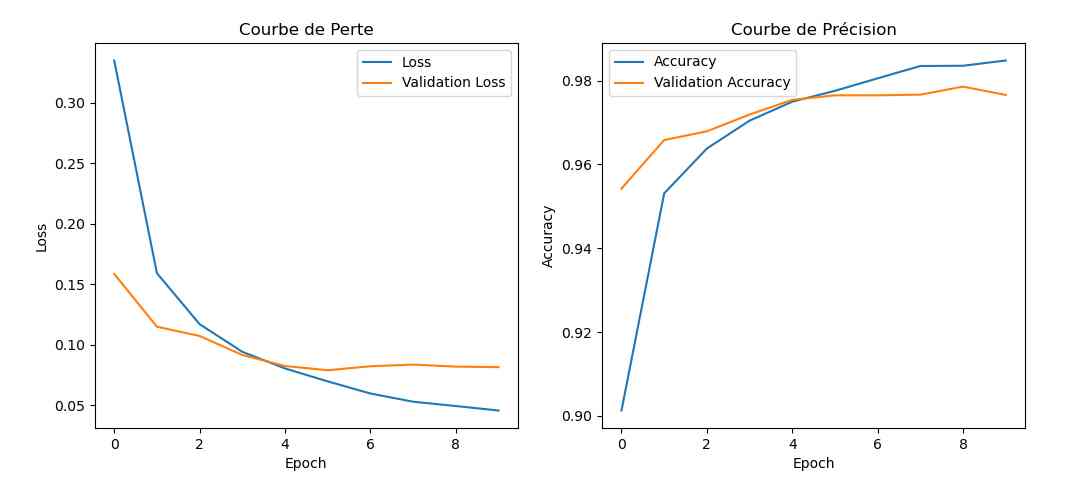
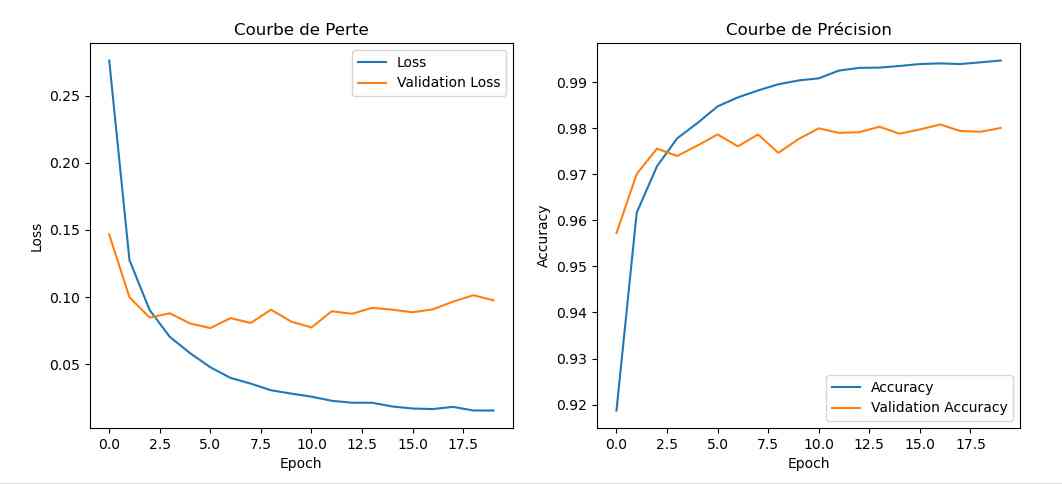
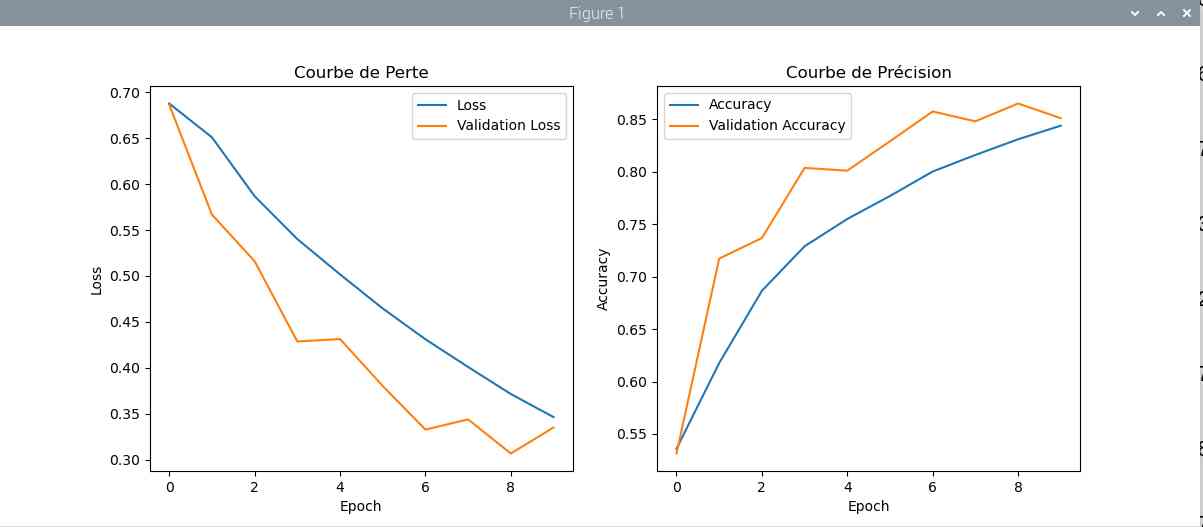
On peut enregistrer le déroulement de l’apprentissage et le représenter sous forme de courbes. C’est ce que fait le programme trace.py.
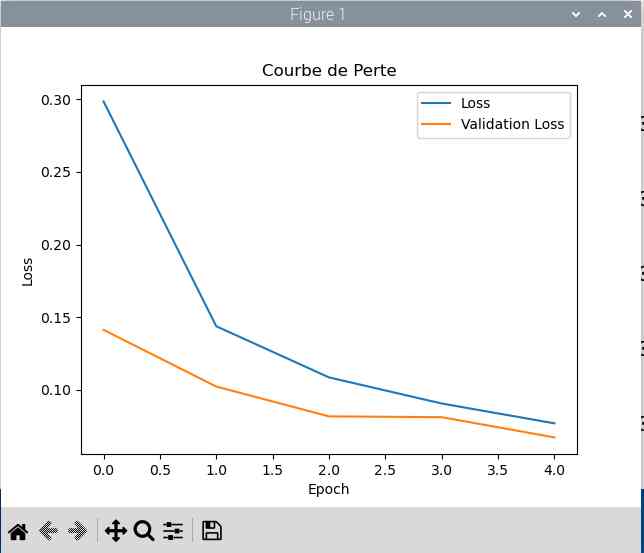 |
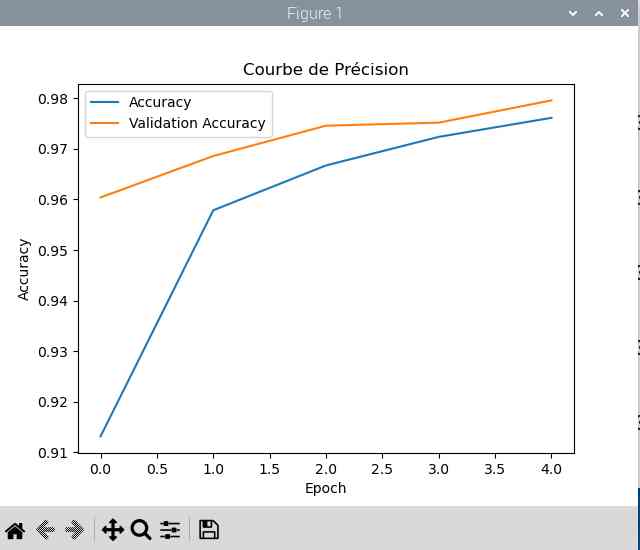 |
On voit bien la progression en fonction du nombre de passes sur les données. La progression augmente et les pertes diminuent.
Essai du modèle pour lire une image
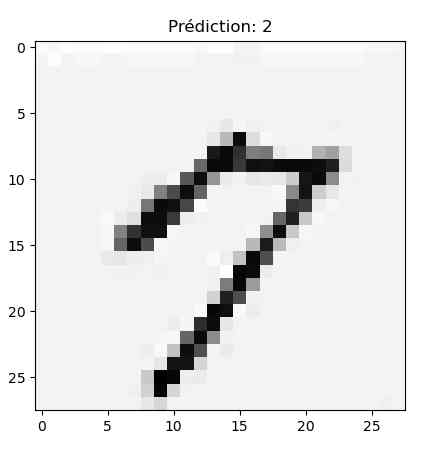
Créer un modèle c’est bien, vérifier qu’il fonctionne, c’est mieux, non ? Alors j’ai écrit des chiffres sur une feuille, et je les ai scannés en noir et blanc pour le test.
 |
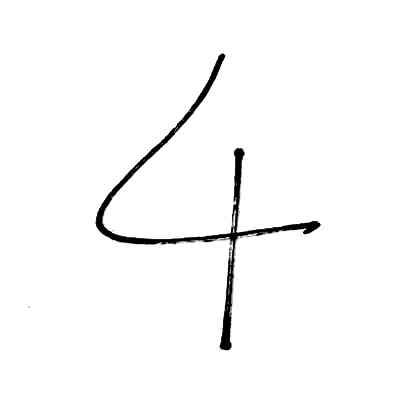 |
 |
et on va lancer le programme de vérification verif.py que vous pouvez télécharger ici :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import cv2 import numpy as np import tensorflow as tf # Charger l'image scannée (par exemple en format jpg) image_path = '/home/pi/test_01/img_2.jpg' # Modifiez avec le chemin de votre image image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # Redimensionner l'image à 28x28 pixels resized_image = cv2.resize(image, (28, 28)) # Normaliser les valeurs des pixels normalized_image = resized_image / 255.0 # Adapter la forme de l'image pour correspondre à celle attendue par le modèle input_image = normalized_image.reshape(1, 28, 28) verif # Charger le modèle sauvegardé model = tf.keras.models.load_model('mnist_model.h5') # Faire une prédiction prediction = model.predict(input_image) predicted_class = np.argmax(prediction) print(f'Le modèle prédit que le chiffre est: {predicted_class}') |
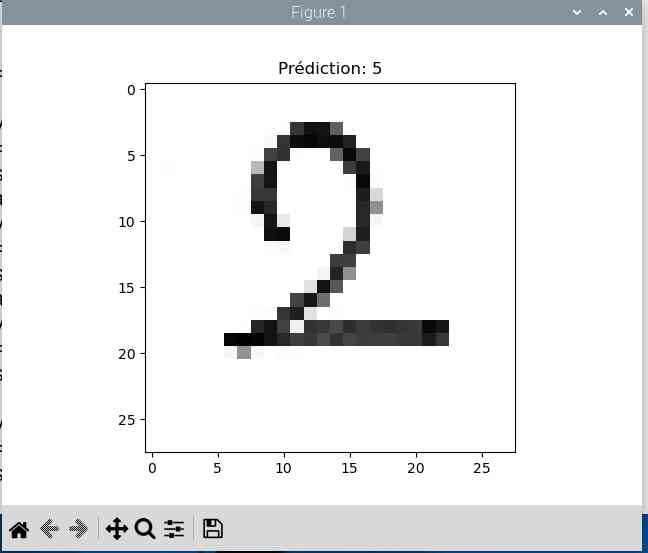
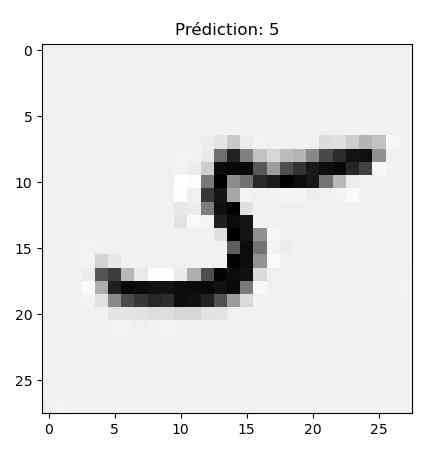
Avec ces premiers chiffres le résultat n’est pas top. Le trait est trop fin et une fois réduit en 28×28 pixels l’IA peine à reconnaitre le chiffre (elle me sort un 2 à chaque fois 😀 ).
On peut aussi améliorer le programme en augmentant le nombre de passes (ici avec 10 passes) et le programme de reentrainement qui atteint 98,48% de certitude.
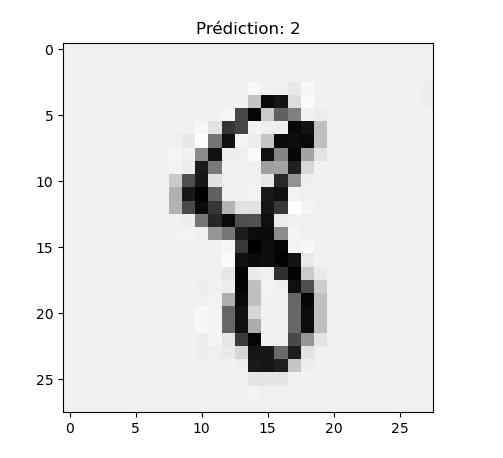
J’ai aussi fait des écritures au marqueur pour épaissir le trait :
 |
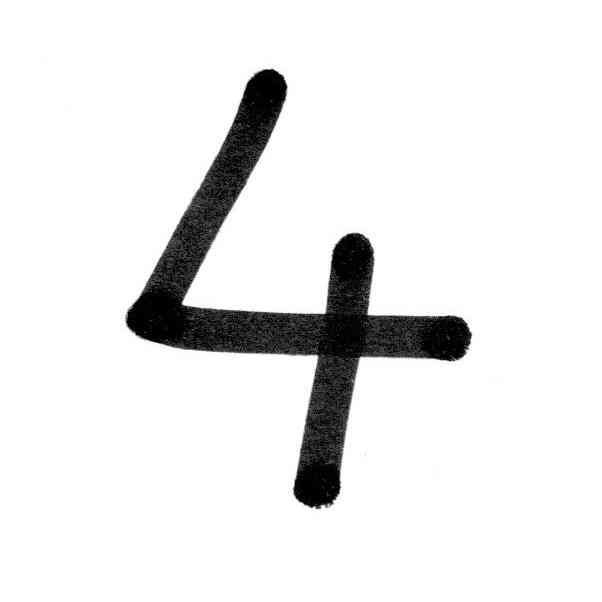 |
 |
Bon, il y a encore du boulot…
 |
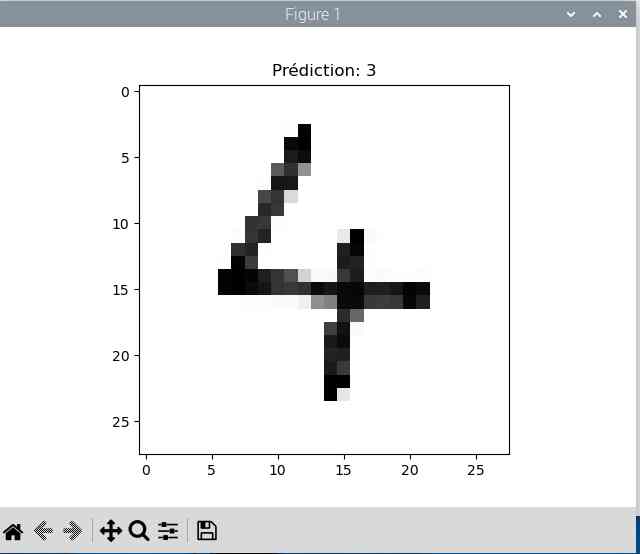 |
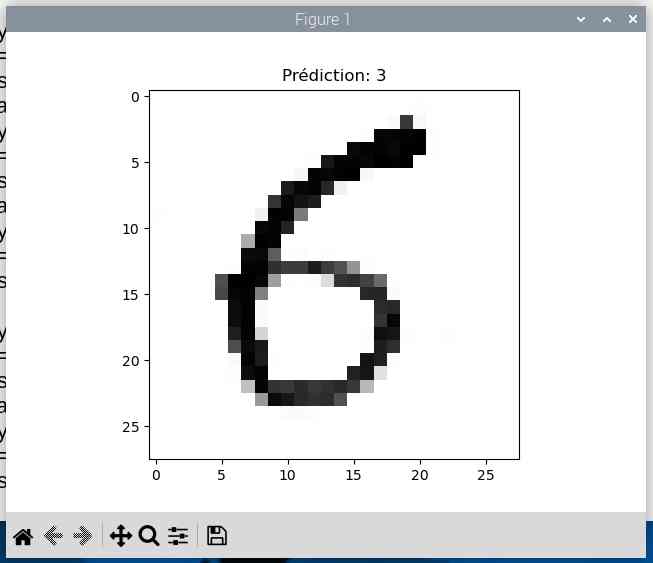 |
Je fais un dernier essai avec 20 passes et plus de neurones (256 au lieu de 128)
Cette fois on atteint 99.47% de précision mais le taux de perte augmente.
 |
 |
 |
 |
Comme chien et chat
Autre essai avec dogs vs cats
Téléchargement des data (2500 images de chiens et 2500 images de chats) pou un Go de data.
curl -L -o ~/Downloads/dogs-vs-cats.zip\
https://www.kaggle.com/api/v1/datasets/download/salader/dogs-vs-cats
Dézippez le fichier dans /home/pi/datasets
Puis lancez le programme d’apprentissage cats_dogs.py.
Là, l’apprentissage est un peu plus long… 10 époques à 1000 seconde/epoch environ soit près de 3 heures. En attendant si vous voulez vous faire une idée de comment les filtres agissent sur les images faites un tour sur cette page… On voit ici l’intérêt de créer ces modèles sur un PC équipé d’un GPU. Je pense que j’ai aussi « bénéficié » du réchauffement (pas le climatique, celui du CPU) qui atteignait allègrement les 85 °C… Eh oui j’ai reçu ce Raspberry Pi 5 avec ses 16 Go de RAM sans le ventilateur piloté (ils arrivent aujourd’hui normalement, je vais équiper tous mes Pi5). Je pense que la température a provoqué un ralentissement du CPU pour le « protéger ». Je vais refaire l’apprentissage avec le ventilateur pour comparer.
Les GPU sont conçus pour traiter un grand nombre de calculs en parallèle, ce qui les rend idéaux pour les opérations de calcul intensif nécessaires au deep learning. Les opérations de calcul matriciel, qui sont au cœur des réseaux de neurones, sont beaucoup plus efficaces sur un GPU. Cela permet de réduire considérablement le temps d’entraînement.
Le Raspberry Pi 5 possède un GPU intégré, mais celui-ci est principalement conçu pour des tâches graphiques de base et ne peut pas rivaliser avec les GPU dédiés de NVIDIA pour les tâches de deep learning et les calculs intensifs. Patience, donc !
Le modèle créé est enregistré sous le nom cat_classifier_model.keras il pèse 31 Mo.
Il va permettre de tester le bon fonctionnement en lisant des images de chiens et de chats avec le programme chat_ou_chien.py :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
import os import cv2 import numpy as np import tensorflow as tf import matplotlib.pyplot as plt # Chemin vers le dossier contenant les images à tester image_folder_path = '/home/pi/test_02/' # Charger le modèle sauvegardé model = tf.keras.models.load_model('cat_classifier_model.keras') # Liste des images dans le dossier image_files = [f for f in os.listdir(image_folder_path) if f.endswith('.jpg')] # Parcourir chaque image et faire une prédiction for image_file in image_files: image_path = os.path.join(image_folder_path, image_file) image = cv2.imread(image_path) if image is None: print(f"Erreur : Impossible de charger l'image {image_file}.") continue # Redimensionner l'image à 128x128 pixels resized_image = cv2.resize(image, (128, 128)) # Normaliser les valeurs des pixels normalized_image = resized_image / 255.0 # Adapter la forme de l'image pour correspondre à celle attendue par le modèle input_image = normalized_image.reshape(1, 128, 128, 3) # Faire une prédiction prediction = model.predict(input_image) predicted_class = 'chat' if prediction[0] < 0.5 else 'chien' print(f'Image: {image_file} - Le modèle prédit que l\'image est : {predicted_class}') # Afficher l'image pour vérification visuelle et attendre l'entrée de l'utilisateur plt.imshow(cv2.cvtColor(resized_image, cv2.COLOR_BGR2RGB)) plt.title(f'Prédiction : {predicted_class}') plt.show() input("Appuyez sur Entrée pour passer à l'image suivante...") |
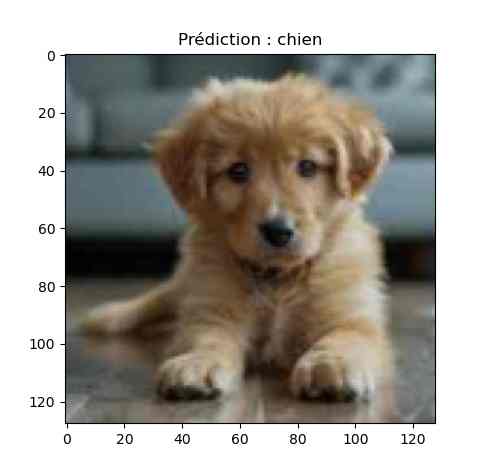
chat_ou_chien 
voilà les images du répertoire de test test_02.
Et le résultat qui n’est pas encore au top… On va essayer d’améliorer tout ça 😀
 |
 |
 |
 |
 |
 |
 |
 |
Tests avec le radiateur ventilé

Il est bien arrivé et je l’ai monté de suite. Le CPU après 5 époques est stabilisé en température à 57°C, nettement plus bas que les 84°C d’hier. Ce ce fait la durée de chaque époque se trouve réduite à 850 secondes au lieu de 1000 et on passe à un apprentissage en 2H30 au lieu de 3H. Le résumé du traitement affiche 850 s et 1s/step au lieu de 1000 s et 2s/step. Il y a donc tout intérêt a bien refroidir son Raspberry Pi 5.
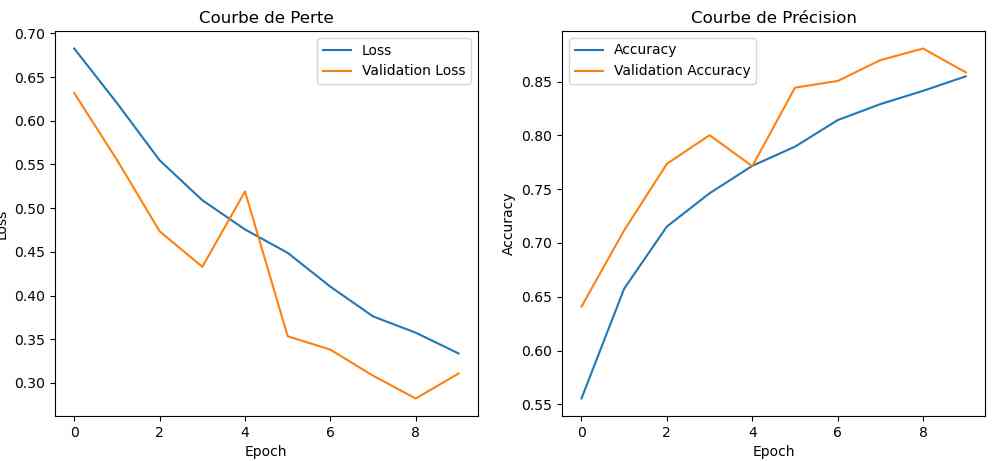
J’ai donc lancé pour la nuit un apprentissage en 20 époques :
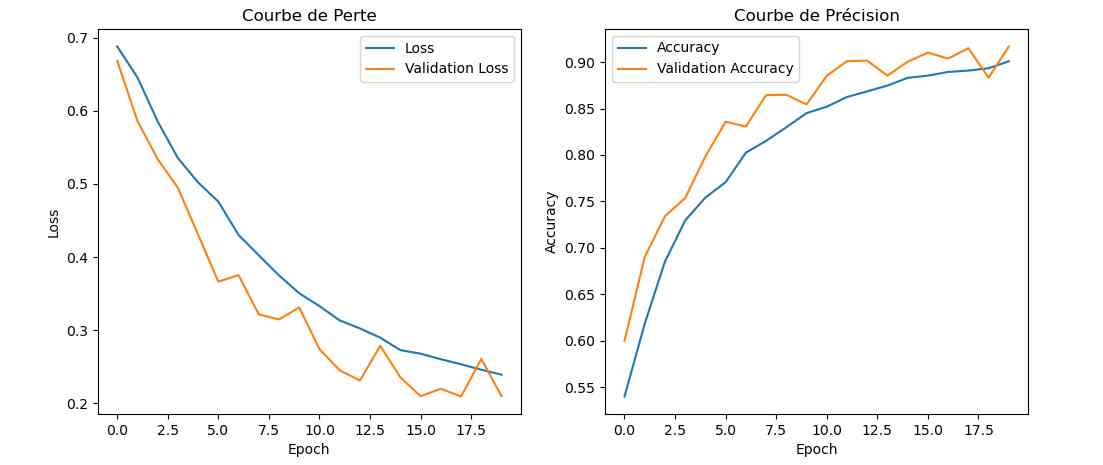
Avec près de 5 heures de travail, on a amélioré le score. J’ai sauvé le modèle sous le nom cat_dog_model_20epoch.keras et modifié en conséquence le programme chat_ou_chien.py. Voyons ce que ça donne en testant la reconnaissance des chats et chiens :
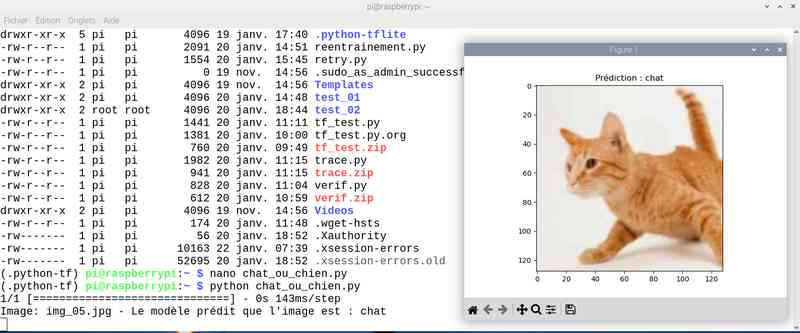
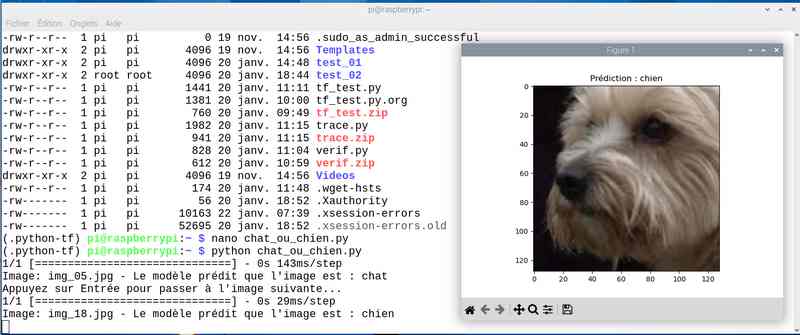
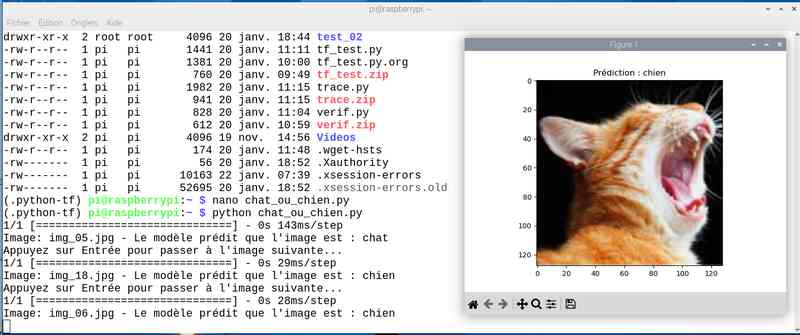
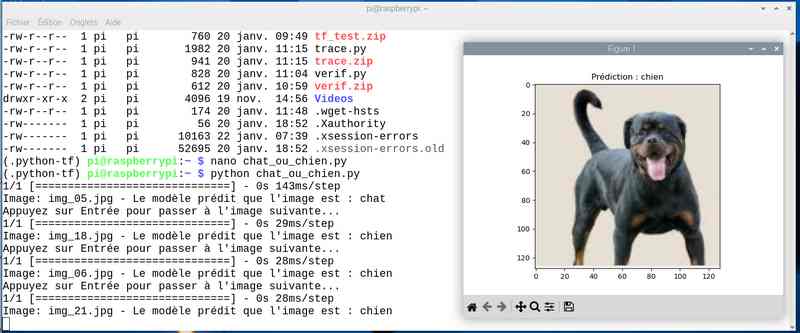
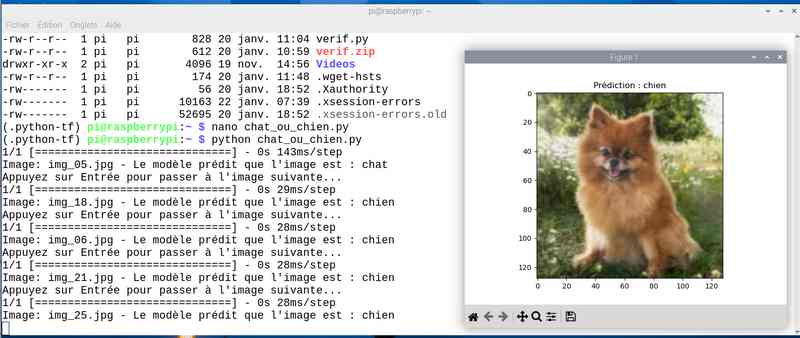
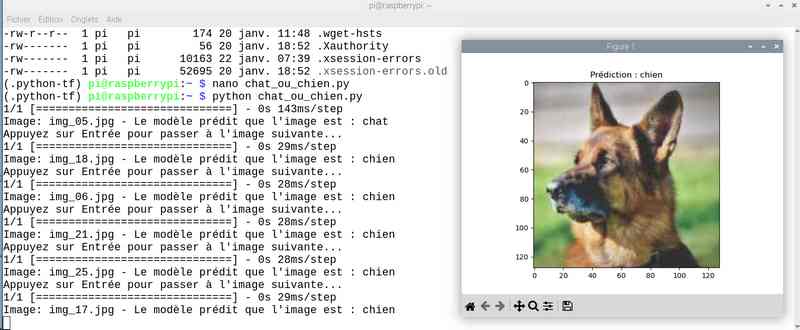
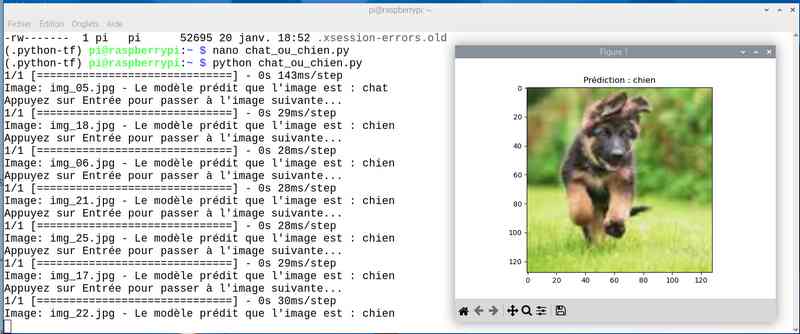
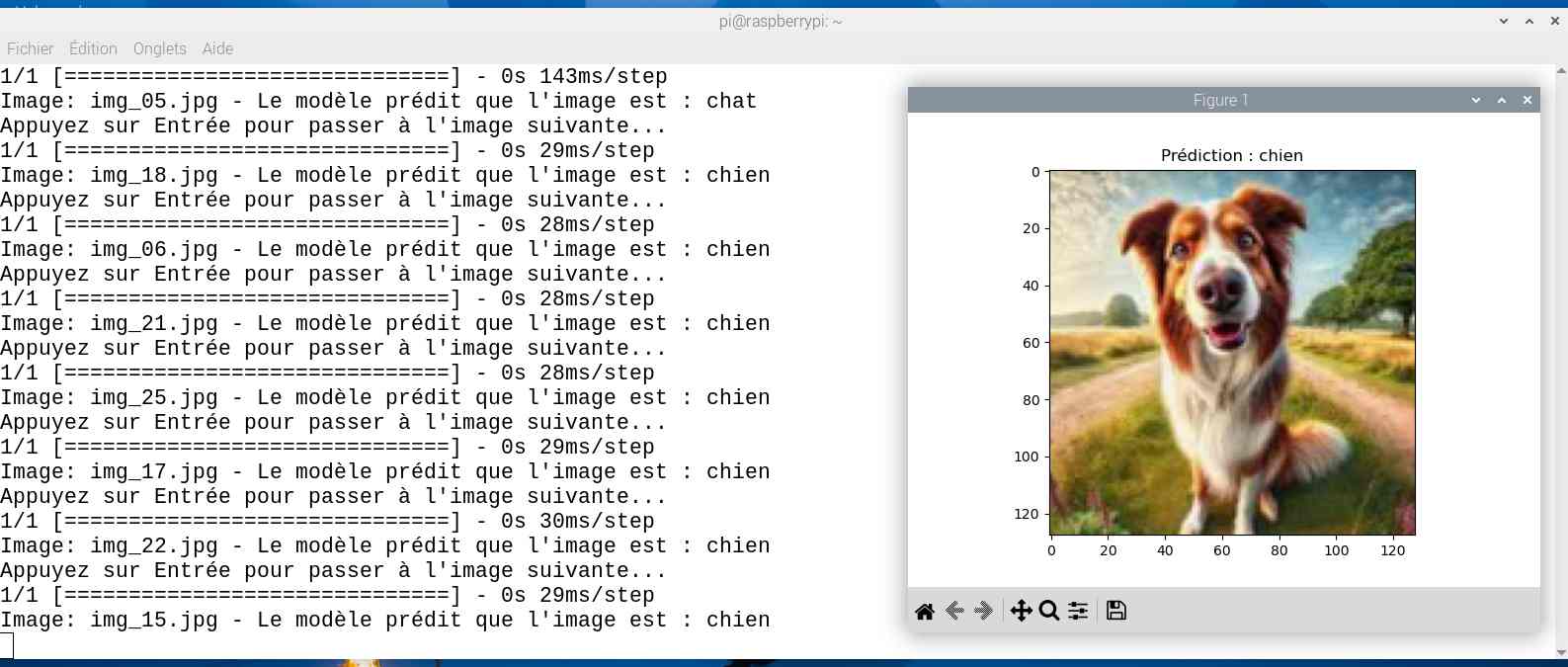
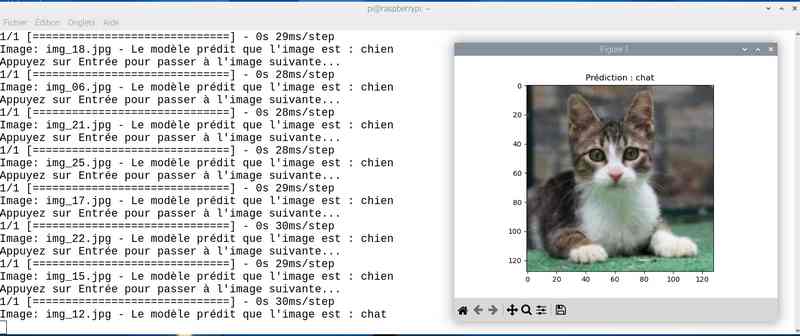
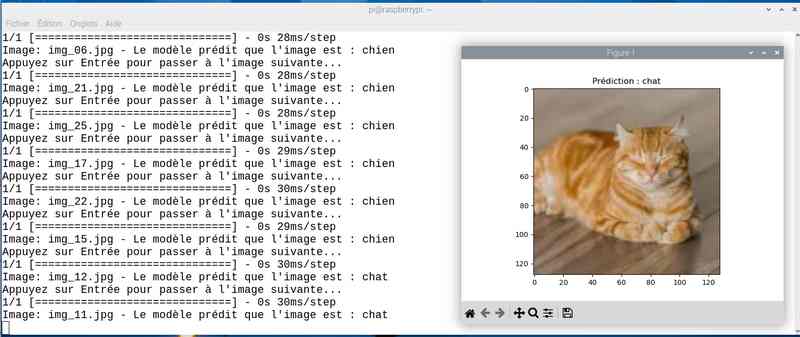
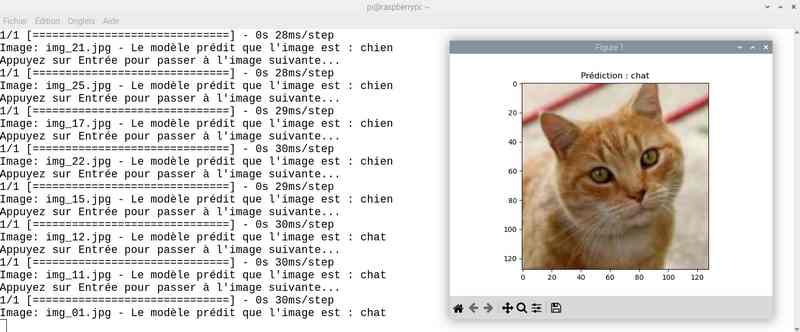
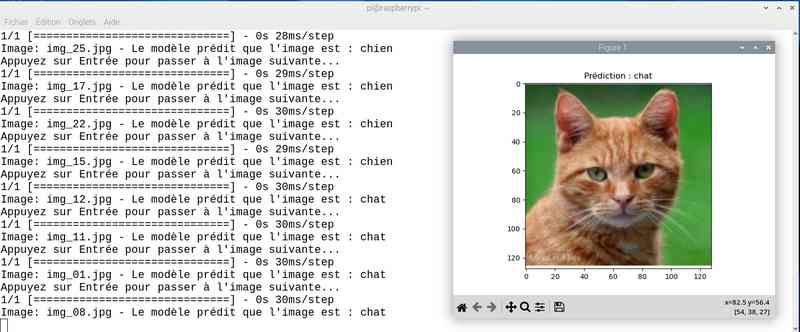
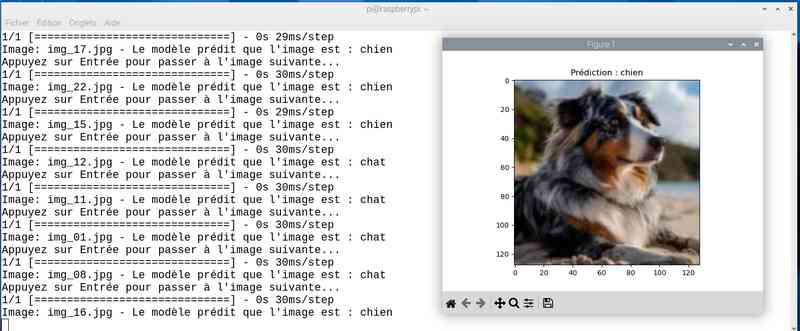
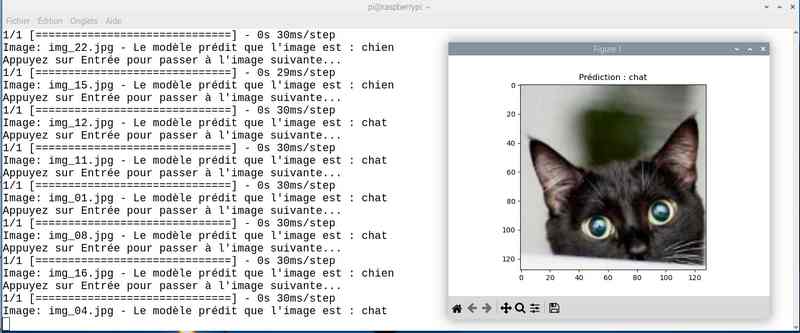
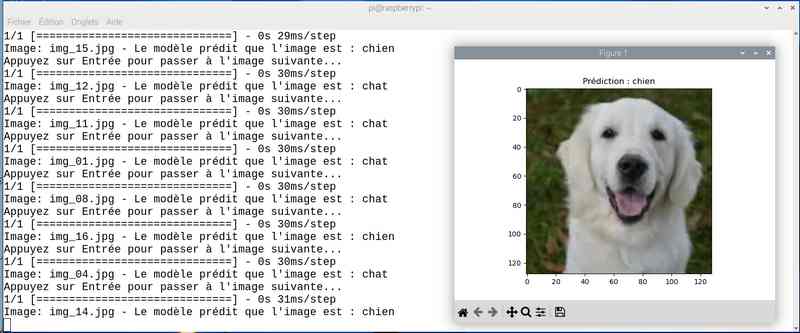
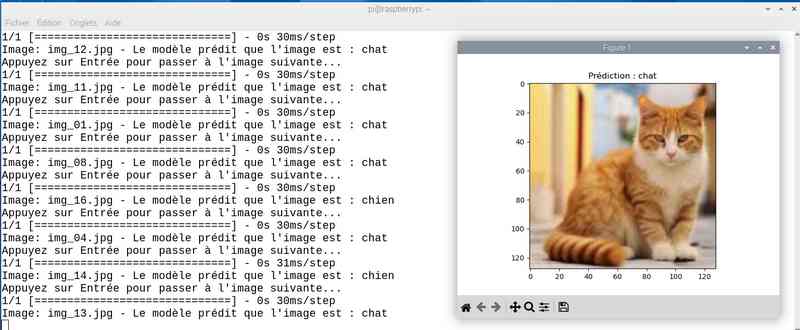
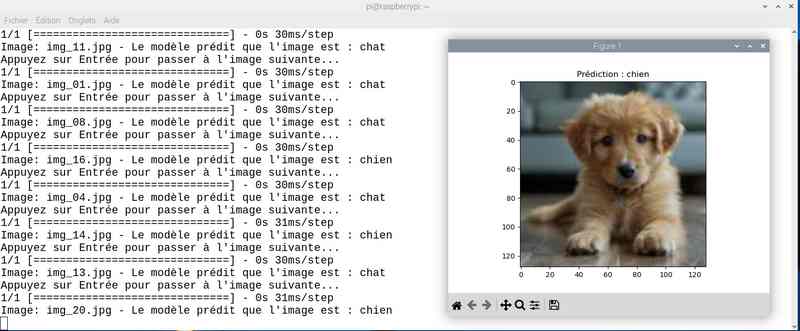
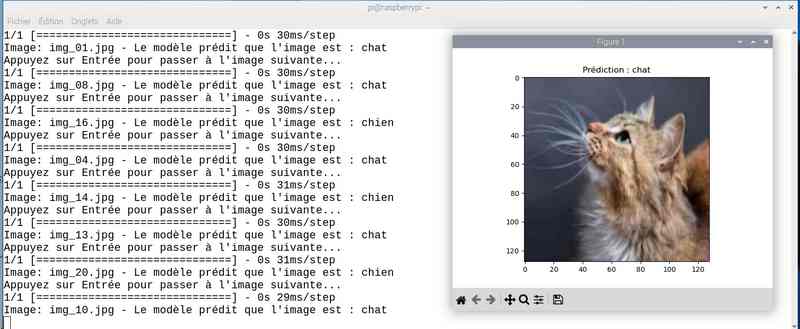

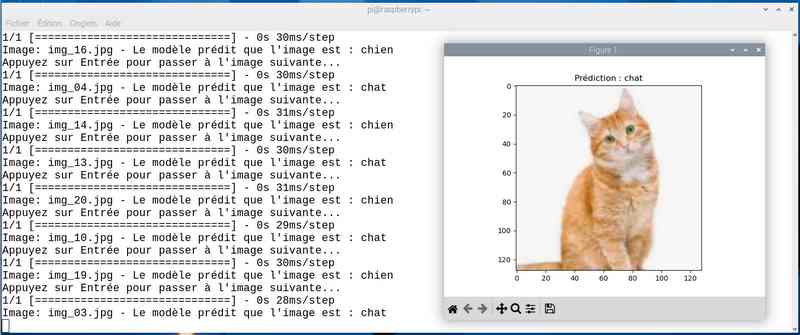
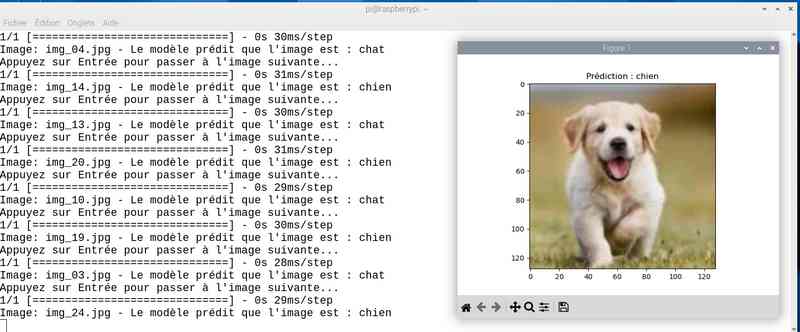
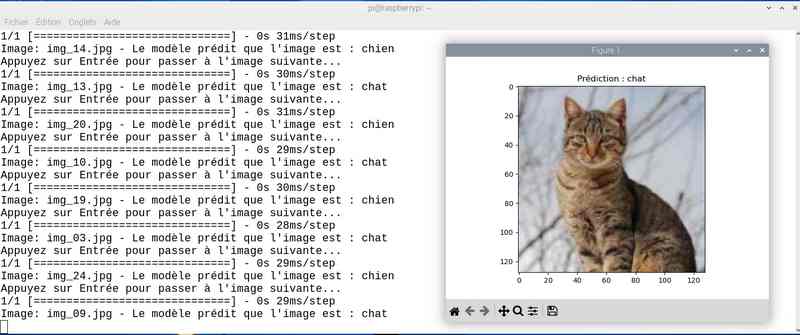
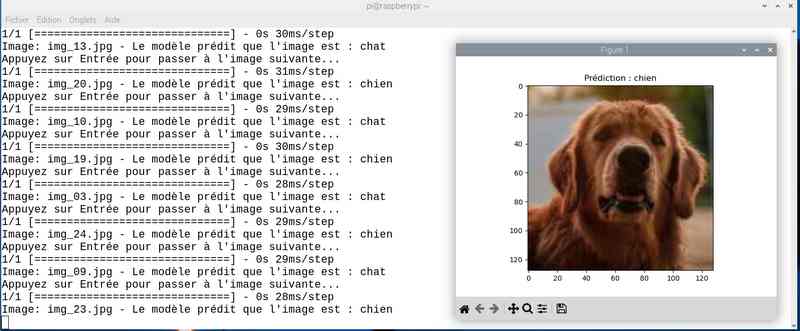
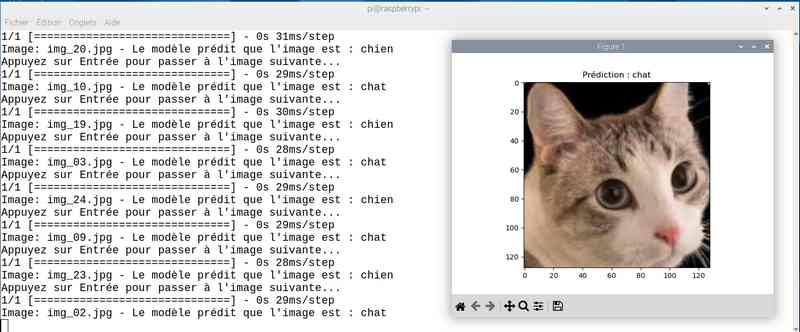
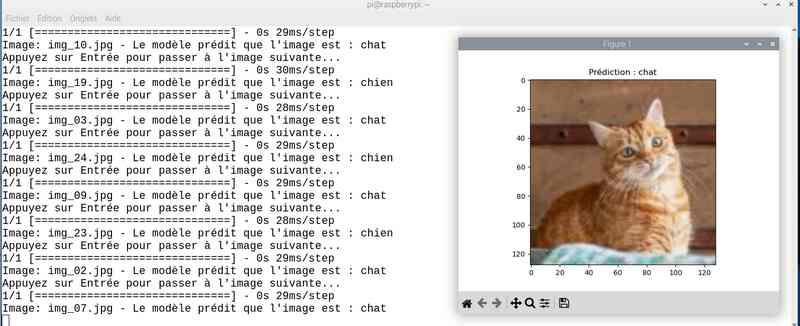
Alors cette fois sur mon jeu de test le résultat est meilleur. Tout est juste sauf le chat qui baille ! Soit une image sur 25 mal identifiée ou 4%…
Ma référence
J’ai bien entendu pas mal lu sur Internet, je vous ai mis les sources ci-dessous mais j’ai aussi bouquiné TensorFlow et Keras : L’intelligence artificielle appliquée à la robotique humanoïde de Henri Laude, publié aux Editions ENI.

L’ouvrage est disponible chez ENI pour 54€ en version imprimée ou 40,50€ en version numérique.
Le début un peu ardu m’a permis de faire remonter en surface des notions mathématiques enfouies très profondément dans ma mémoire, mais qui aident à comprendre les fondamentaux du deep learning et du machine learning.
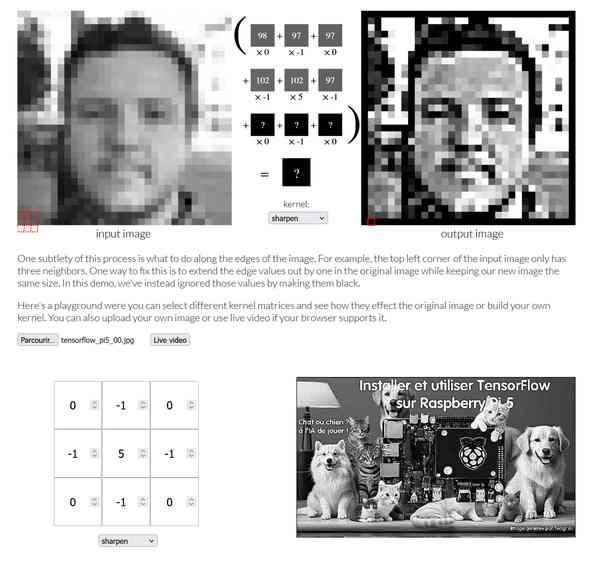
Une autre référence qui aide à saisir comment les matrices s’appliquent aux images (ci-dessus) et où vous pouvez importer vos images ou vidéos : https://setosa.io/ev/image-kernels/
Après la découverte, l’installation et les premières utilisations de TensorFlow, je vais passer aux chapitres sur l’amélioration du modèle. Mon objectif (encore lointain) serait de compiler un modèle et de l’utiliser sur le module Hailo du Raspberry Pi. Mais ça c’est une autre histoire.
Conclusion
Bon, si vous voulez mon avis on approche du résultat mais la fiabilité 100% n’est pas au rendez vous. Après je débute dans ce domaine et j’ai certainement fait des erreurs. Comme dans tous les domaines il va falloir pratiquer pour améliorer.
Si on regarde le bon côté des choses, on a maintenant un Raspberry Pi qui fait tourner TensorFlow, la possibilité de créer un modèle en analysant un (gros) paquet de données. Je vous laisse vous amuser avec tout ça. N’hésitez pas à mettre vos remarques et vos retours dans les commentaires.
Sources
https://www.tensorflow.org/tutorials/quickstart/beginner?hl=fr
https://ulaval-damas.github.io/glo4030/assets/slides/05-cnn-1.pdf
https://setosa.io/ev/image-kernels/
TensorFlow et Keras – Henri Laude
Ping : Installer et utiliser TensorFlow sur Raspberry Pi 5
merci 🙂
Super article ! très complet et très intéressant ! et qui a surtout dû prendre un peu de temps lors des tests et de la rédaction !
😆
ça me motive un peu plus pour continuer mes expérimentations avec le module IA …. et surtout à documenter ! 😛
Merci Fred
euh oui ça représente quelques jours de boulot entre la découverte de l’IA avec Hailo + Coral TPU, le bouquin Tensorflow et Keras de Henri Laude, l’expérimentation (merci Copilot pour le coup de main dans l’approche des programmes !)
mais ça fait aussi partie de l’esprit maker se former pour pouvoir transmettre 🙂
amitiés
François
Je viens de lire votre article sur la reconnaissance d’objets avec TensorFlow et je tenais à vous dire qu’il est vraiment super intéressant. J’ai beaucoup appris grâce à vos explications claires et détaillées. Merci pour ce partage !
Cordialement,
Bonjour,
super article 🙂
J’ai noté quelques typos dans la partie install de tensorflow, dans les lignes:
les options longues (-no-deps et -no-cache-dir) ont un ‘-‘ en moins: –no-deps et –no-cache-dir
et il manque le sous-shell dans l’expression:
qui devrait être:
ARCH=$(
python -c 'import platform; print(platform.machine())')enfin dans les scripts concernant les chiffres, dans tf_test.py le modèle est sauvé sous le nom: mnist_model.keras
mais dans verify.py, c’est: mnist_model.h5 qui est chargé:
et juste au dessus de cette ligne, il y a une commande ‘verif’ qui qui s’est malicieusement glissée 🙂
Cordialement
merci !