

Un premier article vous a appris à reconnaître des objets avec notre Raspberry Pi et OpenCV. Ce nouveau tutoriel vous explique comment aborder la reconnaissance d’objets par apprentissage de votre propre modèle. Nous le ferons en 2 étapes, la collecte de données et la construction de notre réseau de neurones. Au final, le Raspberry Pi sera capable de distinguer 3 races de chats à partir d’une image !
Au sommaire :
Étape 1
Le sujet de reconnaissance
Tout d’abord, meilleurs vœux pour l’année 2019 ! 🙂
Dans ce tutoriel, les images de 3 trois types de chats de race bien connues, seront utilisées.
Il faudra dans un premier temps, télécharger un nombre important d’images de chats. Nous utiliserons la console de développement du navigateur Chrome. A termes, le réseau de neurone artificiel devra être capable de différencier les spécificités morphologiques, des 3 races de matous.
Le chat des forêts Norvégiennes

Le Bengal

Le Chartreux

Le matériel & logiciels.
Nous utiliserons ici, un PC équipé de Ubuntu 18.04 avec Python 3 installé.
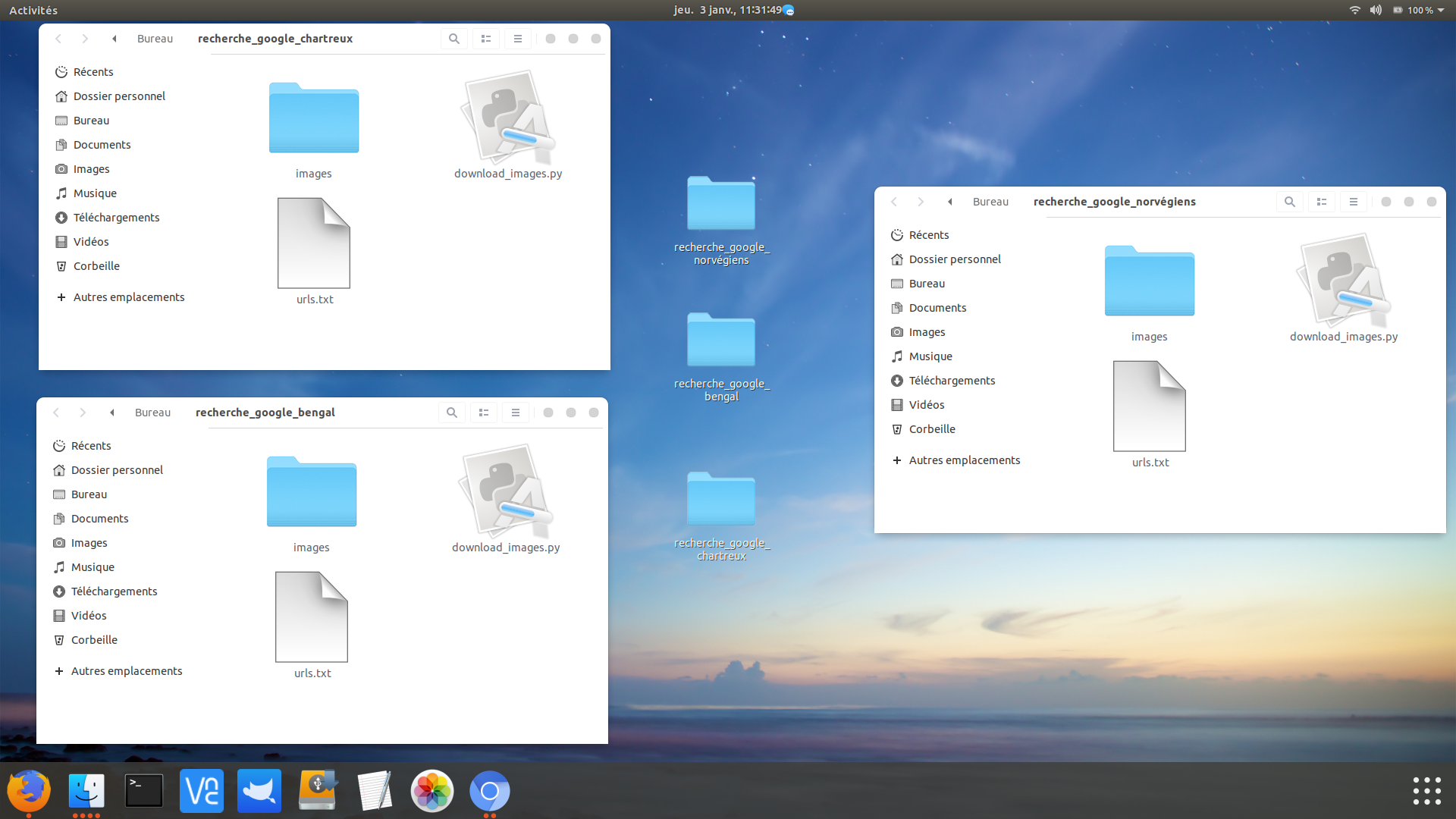
Créez 3 dossiers dans le répertoire de votre choix. Nommez chacun des dossiers, recherche_google_norvegien puis recherche_google_chartreux et recherche_google_bengal. Dans chaque répertoire, ouvrez un fichier texte vide et nommez le download_images.py. Le fichier urls.txt sera le résultat de nos recherches de Google image.
 cliquez sur l’image pour agrandir
cliquez sur l’image pour agrandir
Téléchargez les fichiers textes des urls de milliers d’images.
Il nous faut établir une banque d’images (environ 1000) pour chaque type de chat.Nous utiliserons une fonction du navigateur Chrome de Google, pour télécharger les adresses internet des images et créer un fichier texte.
Un script écrit en Python, se servira du fichier urls.txt pour alimenter chacun des dossiers.
Chrome et sa console de développement
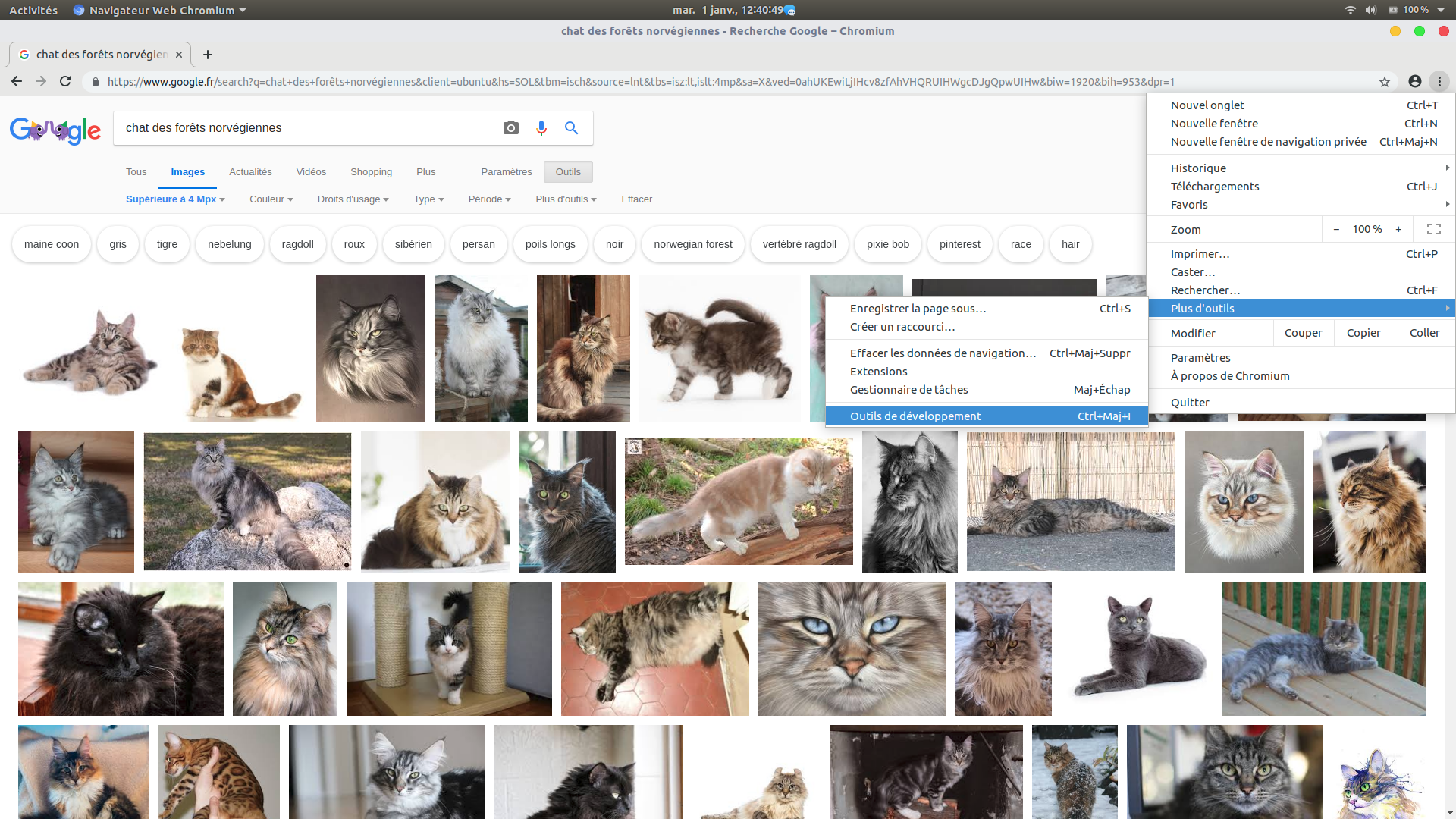
Le navigateur Chrome (tout comme Firefox ou Safari) est équipé d’un outil de développement, qui permet d’exécuter des programmes écrit en JavaScript.
Pourquoi Chrome ? Grâce au puissant moteur de recherche de Google, il est optimisé pour télécharger des milliers d’images d’un sujet précis.
Tapez dans l’onglet image, « chat des forêts norvégiennes ». Cliquez sur le bouton en haut à droite du navigateur, Plus d’outils et Outils de développement.
 cliquez sur l’image pour agrandir
cliquez sur l’image pour agrandir
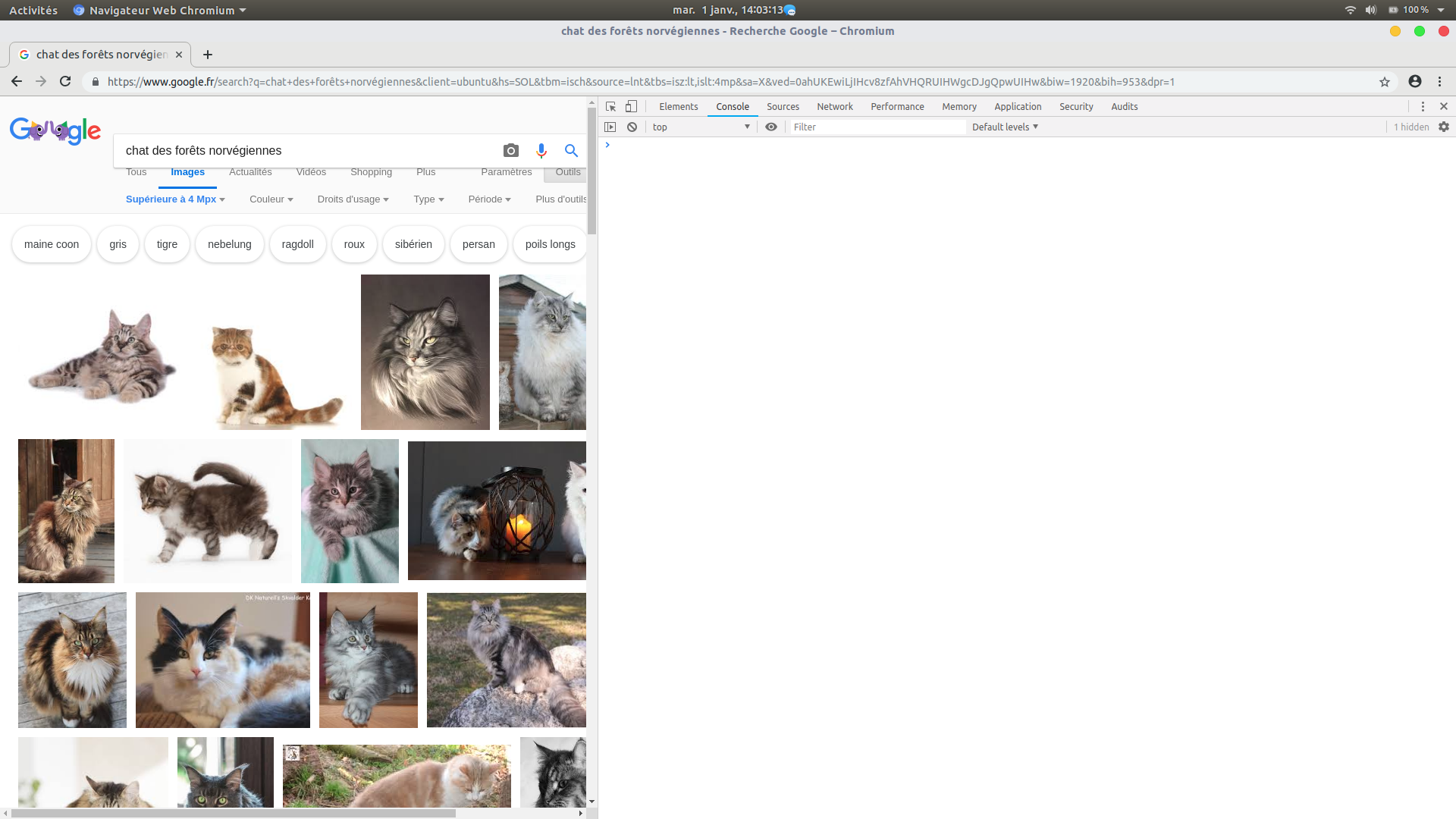
La console apparaît:
 cliquez sur l’image pour agrandir
cliquez sur l’image pour agrandir
Faites défiler les images du haut vers la bas, à l’aide du bouton « scroll » de votre souris. Il faut récupérer 1000 photos de chaque matou. N’hésitez pas à prendre le temps de « scroller » le maximum de photos des chats.
Pour créer ce fameux fichier urls.txt, écrivez dans le menu console, (ligne par ligne) chaque étape du programme JavaScript, avec le module jquery.
|
1 2 3 |
var script = document.createElement('script'); script.src = "https://ajax.googleapis.com/ajax/libs/jquery/2.2.0/jquery.min.js"; document.getElementsByTagName('head')[0].appendChild(script); |
Récupérez les adresse URL de chaque image.
|
1 |
var urls = $('.rg_di .rg_meta').map(function() { return JSON.parse($(this).text()).ou; }); |
Le script ci-dessous écrira chaque URL dans un fichier texte, nommé urls.txt
|
1 2 3 4 5 6 |
var textToSave = urls.toArray().join('\n'); var hiddenElement = document.createElement('a'); hiddenElement.href = 'data:attachment/text,' + encodeURI(textToSave); hiddenElement.target = '_blank'; hiddenElement.download = 'urls.txt'; hiddenElement.click(); |
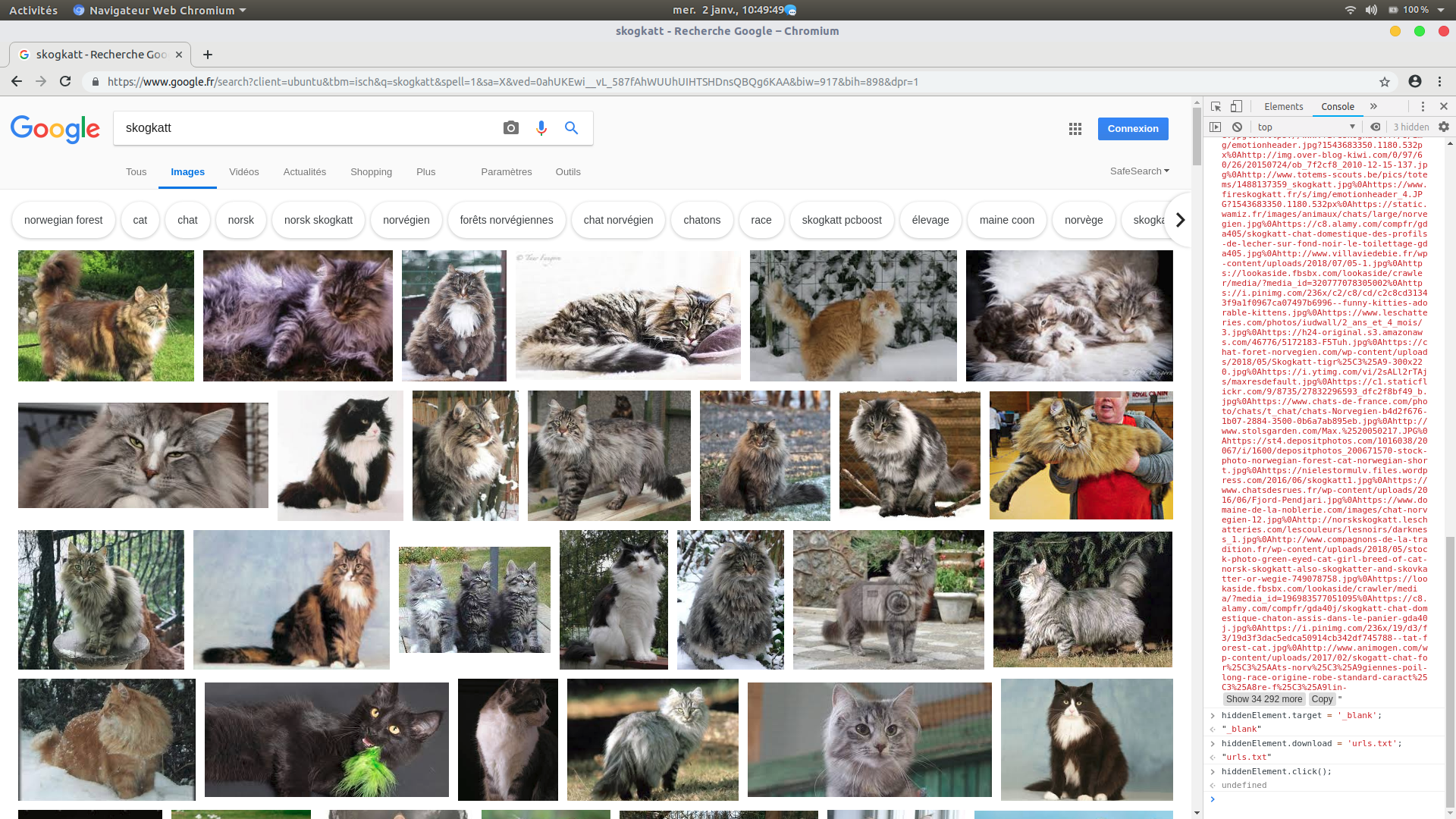 cliquez sur l’image pour agrandir
cliquez sur l’image pour agrandir
urls.txt sera téléchargé dans le répertoire de téléchargement d’Ubuntu (/home/votre_id/Téléchargement). Allez dans le répertoire Téléchargement d’Ubuntu et faites un copier/coller urls.txt dans celui crée par vos soins, recherche_google_norvégiens.
Enregistrez vos images dans un dossier avec Python.
Votre dossier contient le fichier urls.txt, le fichier download_images.py vide de code et un dossier images composé d’un sous dossier norvegiens. Le programme download_images.py va donc utiliser urls.txt pour télécharger les images du norvégien.
Enregistrez le code ci dessous dans download_images.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
#python3 download_images.py --urls urls.txt --output images/norvegiens # import the necessary packages from imutils import paths import argparse import requests import cv2 import os # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-u", "--urls", required=True, help="path to file containing image URLs") ap.add_argument("-o", "--output", required=True, help="path to output directory of images") args = vars(ap.parse_args()) # grab the list of URLs from the input file, then initialize the # total number of images downloaded thus far rows = open(args["urls"]).read().strip().split("\n") total = 0 # loop the URLs for url in rows: try: # try to download the image r = requests.get(url, timeout=60) # save the image to disk p = os.path.sep.join([args["output"], "{}.jpg".format( str(total).zfill(6))]) f = open(p, "wb") f.write(r.content) f.close() # update the counter print("[INFO] downloaded: {}".format(p)) total += 1 # handle if any exceptions are thrown during the download process except: print("[INFO] error downloading {}...skipping".format(p)) # loop over the image paths we just downloaded for imagePath in paths.list_images(args["output"]): # initialize if the image should be deleted or not delete = False # try to load the image try: image = cv2.imread(imagePath) # if the image is `None` then we could not properly load it # from disk, so delete it if image is None: delete = True # if OpenCV cannot load the image then the image is likely # corrupt so we should delete it except: print("Except") delete = True # check to see if the image should be deleted if delete: print("[INFO] deleting {}".format(imagePath)) os.remove(imagePath) |
Voici le résultat:
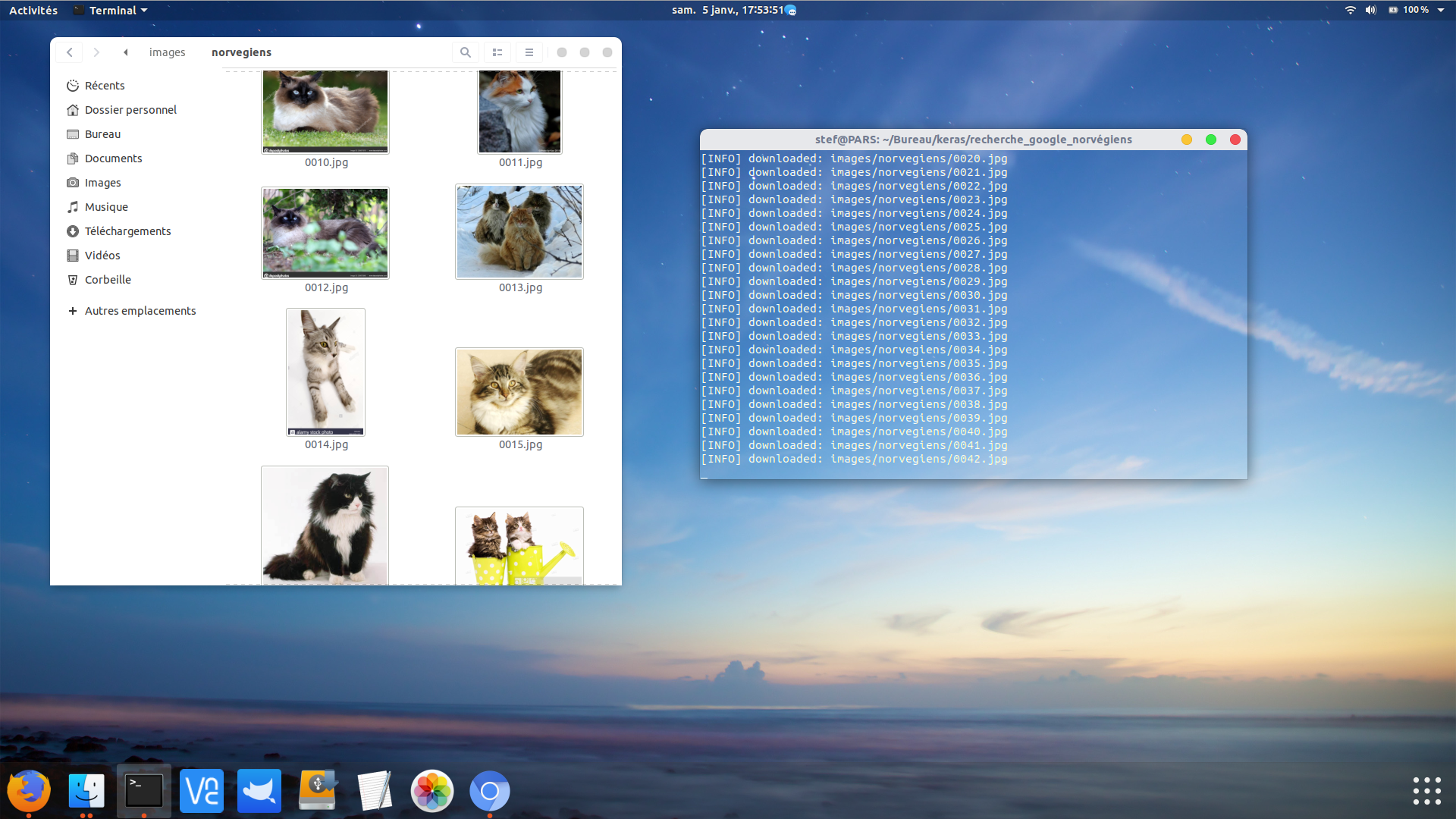 cliquez sur l’image pour agrandir
cliquez sur l’image pour agrandir
Effectuez la même opération, du téléchargement de urls.txt avec Google, jusqu’au programme Python, pour chaque race de chat.
Optimisez vos téléchargements et renommez vos fichiers avec Pyrenammer.
Afin d’avoir de meilleurs résultats en matière de prédiction, il vaut mieux collecter au minimum 1000 images dans chaque répertoire. Si par exemple, votre « scrolling » sur Google n’obtient que 600 images, il faut en télécharger 400 autres. Une astuce consiste à effectuer une deuxième recherche en changeant les mots clés. Par exemple, « skogkatt » l’équivalent de « chat des forêt norvégiennes » dans la langue scandinave. Du coup, vous allez télécharger avec le code Javascript, un autre fichier urls.txt avec les liens d’images différentes.
Dans le fichier download_images.py, remplacez le chiffre 6 en fin ligne :
|
1 2 |
# sauvegarde des images p = os.path.sep.join([args["output"], "{}.jpg".format( str(total).zfill(6))]) |
par :
|
1 2 |
# sauvegarde des images p = os.path.sep.join([args["output"], "{}.jpg".format( str(total).zfill(4))]) |
Ce chiffre correspond au format d’incrémentation des images. En écrivant 6 nous obtenons un format de ce type : 000000.jpg , 000001.jpg , 000002.jpg … Avec 4 ce sera, 0000.jpg , 0001.jpg …
Donc nous aurons un répertoire avec plus de milles images, en totalisant les deux formats.
Nous allons à présent renommer tout les fichiers des répertoires afin d’obtenir un format unique. Cette manipulation permet d’avoir une liste « cohérente » pour le futur modèle d’entraînement.
Pour cela, installez un utilitaire bien pratique, nommé « pyrenammer ». Le paquet deb est disponible à cette adresse
 cliquez sur l’image pour agrandir
cliquez sur l’image pour agrandir
Nous souhaitons renommez l’équivalent de 1000 images (ou plus). Pour notre cas, le format serait, en partant de la première image : 0000.jpg et la dernière 9999.jpg. A condition d’avoir 10000 images téléchargées, dans chaque dossier des chats. Double cliquez sur un des répertoires, vous verrez à gauche, la liste des fichiers dans les deux formats. Allez en bas à gauche de la fenêtre, renommez la règle du nom de fichier renommé par : {num4}.jpg. Cliquez sur le bouton Aperçu en bas à droite. Si tout est cohérent, cliquez sur Renommer.
Conclusion.
Nous avons désormais, toutes les images pour établir notre propre modèle. Ici, nous avons utilisé Ubuntu 18.04, mais vous pouvez tenter les manips avec Windows et MacOS. On peut aussi tentez le coup avec Chromium sur Raspbian.
Pour la deuxième partie du tutoriel, il nous faudra une machine suffisamment puissante, pour construire le modèle de prédiction. Les essais ont été effectués avec un PC 64 bits équipé d’un processeur Intel Core3 et 6 Go de mémoire vive. (entre nous, mon ordi pédale…)
Nous ne sommes pas sur Framboise 314 pour rien, alors nous évoquerons bien sur, le portage du programme sur la Raspberry Pi. Du moins, une fois que le modèle sera créé sur une machine plus puissante comme un PC et sa propre architecture.
Voilà ! J’espère que cette première partie, vous a permis de télécharger la quantité d’images nécessaire au modèle. A plus tard, dans le prochain tutoriel sur Framboise 314. 🙂
Bonne manip dans le labo de l’I.A ! 😀
Chouette article qui me met l’eau à la bouche pour la suite (d’autant que le logos Google AI, Tensorflow apportent encore plus de teasing ) !
Merci !
‘’Est ce que la console de développement de chrome sera stable, sur le long terme?’’
Qu’entendez-vous par ‘long terme’ ? Avez-vous pris en compte l’accélération sans cesse croissante du réchauffement climatique ? Si on s’en réfère aux théories de Darwin, il est fort probable que le skogkatt subisse ses effets. Ce qui probablement le débarrasserait de son épais pelage sur du plutôt moyen terme. Les neuroneS du réseau pourraient alors douter (ca doute un neurone ? ) et ne plus etre en mesure de différencier cette race de celle du chat de gouttière européen.
Bonjour,
Pour les paresseux (j’en suis), ce package python permet de charger des images via Google
$ pip install google_images_download
Un exemple d’utilisation :
python3 google-images-download.py –keywords « chats, cochons »
Le lien
https://pypi.org/project/google-images-download/1.0.1/
Amusez-vous bien
Raymond
J’ai essayé les scripts de l’auteur et ils fonctionnent très bien meme dans d’autre navigateur (moyennant quelques adaptations).
Il y a une autre méthode qui permet de récupérer très facilement beaucoup d’image, c’est d’utiliser les API de recherche BING (https://azure.microsoft.com/fr-fr/services/cognitive-services/bing-image-search-api/). A haute dose, ces services sont bien sur payants, mais il est possible d’obtenir une api key d’essais de 7 jours et par la suite d’utiliser un compte gratuit pour continuer à utiliser ces services. Un des avantages de cette méthode est qu’elle permet aussi de récupérer les images au format des thumbnails, ce qui est beaucoup plus léger comparé à la récupération des images originelles depuis leurs emplacements et qui peuvent etre de dimensions très aléatoire. Cela garanti aussi que toutes les images sont bien disponibles.
La page https://docs.microsoft.com/en-us/azure/cognitive-services/bing-image-search/ propose des exemples d’utilisation de l’API pour plusieurs langages de programmation (c# Java Node PHP Python et Ruby) ainsi que toute la documentation.
Bonjour
certains mettent leur vraie adresse mail , qui n’est pas publiée. mais ça permet de les contacter…
je voulais juste vous prévenir avant de supprimer les commentaires que les réponses disparaissent aussi, que vous ne soyez pas étonné
vous pouvez toujours me contacter via contact[AT]framboise314.fr
cordialement
françois
Bonjour Stéphane,
Merci pour ce tuto, j’ai pu réaliser la première partie, mais je bloque sur le script download_images.py, j’ai une erreur d’indentation sur le bloc try: ligne 24… !!!
Avez-vous une piste de solution ?
Merci,
Alex
Bonjour Alexandro,
Votre problème d’indentation viens de la rédaction du code. La ligne 24 correspond à une boucle « try ». Avec Python, les boucles doivent se « décaler » du programme principal. Vous pouvez utiliser la touche tabulation au début de la ligne 24.
J’ai mis à jour le code de download_images.py sur le blog. Les commentaires sont en Anglais.
Vous n’avez plus qu’à copier / coller le code 🙂
@+
Bonjour Stéphane,
Merci pour ta réponse, c’est bien ce que j’avais essayé de faire mais j’avais dû me tromper sur certaines indentations…
Pour info, j’ai dû installer imutils via pip install imutils et le placer le(s) répertoire(s) « imutils » dans le(s) répertoire(s) recherche_google_xxx.
J’avais ensuite un autre problème, il n’arrivait pas à télécharger tous les fichiers… C’était le i de nom de répertoire images que j’avais mis en majuscule… inattention…
Ensuite tout a fonctionné nickel.
J’attend donc la suite avec impatience, merci encore Stéphane.
Cordialement,
AlexandrO
Bonsoir à tout le fofo 🙂
Pour raison professionnelle, je n’aurais pas le temps (pour l’instant), de publier la seconde partie de l’article.
Vous pouvez en attendant, vous inspirez du site d’Adrian Rosebrock à cette adresse : https://www.pyimagesearch.com/2018/09/10/keras-tutorial-how-to-get-started-with-keras-deep-learning-and-python/
L’auteur est Américain, si vous avez installé le navigateur Chrome, vous pouvez utiliser l’option de traduction (approximative) en Français.
@++
Ping : I.A : Créez votre propre modèle de reconnaissance d’objets (1er partie)
Bonjour, et merci pour cet article que je trouve très pédagogique.
J’avance bien de mon coté : mon projet consiste à reconnaître au fil de l’eau les véhicules, animaux ou humains qui passent devant une caméra fixe, laquelle envoie des images à chaque fois qu’il se passe quelque chose.
J’ai actuellement un dataset de 1000 images environ par classes : CHAT, VOITURE, HUMAIN, RIEN
Ma question est la suivante : sur beaucoup d’image, il n’y a RIEN à reconnaître, car l’élément déclenchant est passé plus vite que la vitesse de réaction de la caméra.
Sur ces images il n’y a donc rien d’autre que le décor ambiant, toujours le même : des arbres, une cour, un chemin, un mur…..
Je ne sais pas quelle stratégie adopter, car à chaque image de « RIEN », mon réseau ne l’associe jamais à « RIEN », il répartit systématiquement son pourcentage sur les autres classes CHAT, VOITURE, HUMAIN, avec à chaque fois une répartition très différente. A ma grande déception, il n’attribue jamais le moindre pourcentage à la classe « RIEN ».
Peut-être devrais-je carrément oublier la classe RIEN, mais comment interprêter le résultat quand RIEN n’est visible ?
Mon problème doit être banal, j’ai presque honte de ne pas trouver tout seul la stratégie….
Merci d’avance pour votre aide.
Gérard
Bonjour,
Merci pour ce tutoriel riche !
Je ne trouve pas la partie 2 est-elle en ligne ?
Cordialement
Robin
Bonjour,
Est-il possible de créer ça propre banque de données.
Prendre chaque objets en photo, leur donner un noms.
Puis faire entre l’objet dans le champs de vision de la caméra.
Et qu’il nous donne le noms de l’objet?
Merci
Salut à tous, est ce que le projet est achevé ou existe il une deuxième partie concernant l’entrainement proprement dit, ou un tutoriel complet? merci pour vos réponse, cordialement
Salut à tous ,
Je me demande si le projet à été fini , impossible de mettre la main sur la seconde partie !
Le projet est très intéressant et j’aimerais le concrétiser de mon côté
Bien cordialement