


Fredéric (Frederic JELMONI alias Fred Robotic) avait déjà présenté des articles sur le Blog, dont le « Raspberry Pi sur la planète Mars« . Membre (et vice-Président) de l’association de robotique Caliban Fred utilise l’IA pour agrémenter le fonctionnement des ses robots et il a fait un énorme travail sur la création de modules d’IA avec Hailo pour le Raspberry Pi 5, et il m’a proposé de partager sa documentation sur le blog. Vous retrouverez en fin d’article les liens vers le Github qui contient la totalité des travaux de Fred.
Au sommaire :
Créer et Entraîner son propre IA pour le module AI HAILO du Raspberry PI5
L’objectif est ici de :
- créer une IA de reconnaissance de formes simples
- sur la base de ses propres photos ( ou vidéos )
- et qui puisse exploiter la puissance d’un module IA d’un Raspberry PI5
Nous pouvons distinguer 4 grandes étapes décrites plus bas :
- la création de son jeu de données : le dataset
- l’entraînement du modèle IA avec YOLOv8
- la conversion, ou compilation, du modèle pour le module HAILO
- le déploiement et les tests sur le Raspberry PI
Création de son jeu de donnée
Pour la création du Dataset, différentes méthodes se présentent à nous :
- Tout réaliser en local à l’aide d’outils spécifiques et/ou scripts Python
- Utiliser une plateforme spécialisée, en ligne, dans le cloud
J’ai commencé, dans un premier temps, par réaliser mon jeu de donnée en local, pour ensuite réaliser des versions plus complexes et certainement plus efficaces sur Roboflow, une plateforme particulière intéressante pour créer et stocker des Dataset.
Je vais donc décrire ces deux approches.
La création du dataset consiste à créer une collection d’images représentatives des objets que l’on souhaite détecter.
Ces images devront être annotés avec l’emplacement et le nom de l’objet visible.
Mais il y a quelques éléments à prendre en considération :
- le format du dataset : YOLOv8
YOLOv8 (You Only Look Once v8) est une version avancée de la célèbre famille de modèles YOLO utilisée pour la détection d’objets, la segmentation d’images et la classification.
YOLOv8 est principalement un modèle d’IA de détection d’objets qui utilise un format spécifique pour les datasets.
Ce modèle d’IA est particulièrement adapté et préconisé pour le module HAILO du Raspberry PI.
Autres éléments importants :
-
YOLOv8, comme ses prédécesseurs, fonctionne mieux avec des images carrées.
-
la dimension des images de 640×640 pixels (par défaut pour YOLOv8) –> Un bon compromis entre précision et performance.
-
l’arborescence des répertoires
-
le format des fichiers d’annotation
-
le nombre de classes
-
le nommage des classes ( ex: « carré vert », « rond rouge », triangle « jaune », …. )
Voici un exemple d’organisation du dataset au format YOLOv8 :
|
1 2 3 4 5 6 7 8 9 10 11 |
Mon_Dataset/ ├── data.yaml ├── test │ ├── images │ └── labels ├── train │ ├── images │ └── labels └── valid ├── images └── labels |
On y trouve :
- le fichier « data.yaml » qui contient la liste des sous répertoires, le nombre et le nom des classes
- 3 répertoires : « train », « valid », « test »
- contenant chacun 2 sous répertoires : « images » et « labels »
Le fichier label, au format texte (.txt) est donc stocké dans un répertoire différent de l’image correspondante,
mais le lien entre ces deux fichiers est fait par leur nom ( mon_image_12345.jpg –> mon_image_12345.txt )
Enfin, les données doivent être répartis selon un certain ratio :
- 70 % pour le training –> répertoire « train »
- 15 % pour la validation –> répertoire « valid »
- 15 % pour les tests –> répertoire « test »
Nous pourrions également envisager un répartition de 70/20/10 , ou 75/15/10 …. à tester …
Création du Dataset en local
J’ai réalisé de nombreux tests de création de dataset, avec 12 objets différents (12 classes), différents fonds, plusieurs types d’éclairage … mais ça commençait à se compliquer un peu … surtout quand le résultat attendu n’était pas vraiment au rendez vous ….
J’ai donc réduit la voilure avec un Dataset composé de 2 classes : « carré vert » & « carré rouge »
Les fichiers sources, de mes derniers tests, son disponibles dans mon repo GitHub :
https://github.com/FredJ21/RPI5_AI_Hailo_tests
|
1 2 3 4 |
git clone https://github.com/FredJ21/RPI5_AI_Hailo_tests cd RPI5_AI_Hailo_tests ls -al Dataset/Fred_Dataset/images_HD_2 |
Les photos
J’ai donc fait plein de photos de mes pièces en veillant, bien évidemment, à réaliser autant de photos pour chacune d’entre elle :
- 75 photos pour le training dans le répertoire « train » (*)
- 15 photos pour la validation dans le répertoire « valid » (*)
- 15 photos pour les tests dans le répertoire « test » (*)
*( pour chaque classe d’objet !!! )
Pour réaliser ces photos, c’est très simple ! il suffit d’utiliser la caméra du Raspberry PI !
Avec la commande suivante :
|
1 |
rpicam-jpeg --camera ${CAMERA} --output ${FILE} --timeout ${TIMEOUT} --autofocus-mode manual --lens-position 0.0 |
Cela produit une image haute définition de 4608×2592 pixels et d’environ 3,3 Mo.
 |
 |
 |
 |
Le script « prendre_une_photo.sh » ( dans le répertoire [GIT]Scripts/bin ) permet d’automatiser la séance !
en prenant une photo toutes les 2 secondes et en répartissant les clichés dans les répertoires : train, valid, et test.
Le nom des fichiers correspond à un horodatage de type timestamp.
|
1 2 3 4 5 6 7 8 |
ls -al Dataset/Fred_Dataset/images_HD_2/test/*jpg -rw-r--r-- 1 pi pi 2994083 15 déc. 00:47 Dataset/Fred_Dataset/images_HD_2/test/1734220016.jpg -rw-r--r-- 1 pi pi 3009538 15 déc. 00:47 Dataset/Fred_Dataset/images_HD_2/test/1734220032.jpg -rw-r--r-- 1 pi pi 3367522 15 déc. 00:47 Dataset/Fred_Dataset/images_HD_2/test/1734220038.jpg -rw-r--r-- 1 pi pi 3281630 15 déc. 00:47 Dataset/Fred_Dataset/images_HD_2/test/1734220046.jpg -rw-r--r-- 1 pi pi 3273484 15 déc. 00:47 Dataset/Fred_Dataset/images_HD_2/test/1734220051.jpg ../.. |
Les labels
Il est temps maintenant d’annoter les images.
Cette opération d’étiquetage consiste à dessiner un cadre de délimitation autour des objets présents sur les photos, tout en précisant sa classe ( « carré vert » ou « carré rouge » ) ?
Cette opération nécessite une certaine précision et un peu de patience !!!
Le cadres doit être serré mais pas trop proche.
Il ne doit pas y avoir de sur ajustement dans le cas ou plusieurs objets sont présents sur la même photo.
( mais par soucis de simplification, mes images ne comportent qu’un seul objet )
Dans mon cas, j’ai choisi de réaliser des photos distinctes par type d’objet. J’ai donc qu’un seul objet par photo.
Je souhaitais également réaliser cette opération complètement en local, sur mon Raspberry PI5, à l’aide d’un utilitaire très léger.
J’ai utilisé « YOLO-Label » que l’on peut trouver ici : https://github.com/developer0hye/Yolo_Label
« YOLO-Label » est également disponible dans une version pré-compilé pour le Raspberry PI 64bits (version Debian/PiOS 12 bookworm) sur mon GIT :
|
1 2 3 |
cd RPI5_AI_Hailo_tests//Scripts/bin/Yolo_Label/ chmod +x YoloLabel ./YoloLabel |

(animation d’exemple du site officiel)
L’utilisation est très simple et doit être réalisé sur l’ensemble des photos de DataSet.
- on sélectionne le répertoire de travail qui contient les images
- on sélectionne la liste des classes ( labels_list.txt )
- on choisit une classe
- on dessine en carré pour délimiter notre pièce
- next …
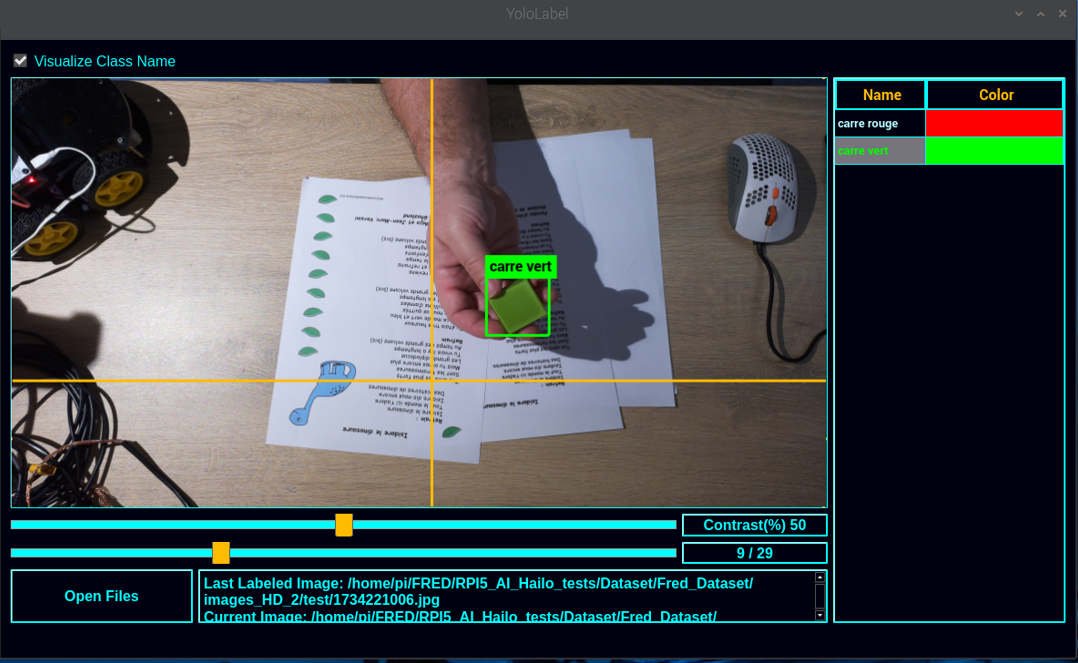 |
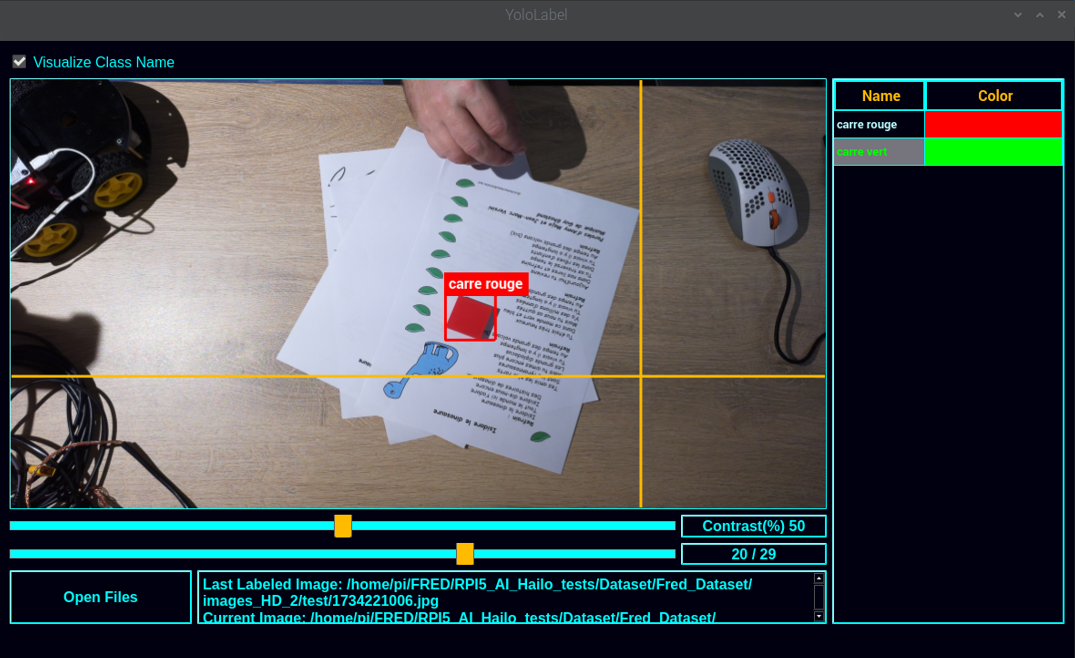 |
Tous les fichiers jpeg sont maintenant accompagnés par un fichier texte du même nom mais avec l’extension .txt .
|
1 2 3 4 |
1734219226.jpg --> 1734219226.txt 1734220832.jpg --> 1734220832.txt 1734220572.jpg --> 1734220572.txt 1734219623.jpg --> 1734219623.txt |
Ces fichiers contiennent 5 valeurs numériques :
|
1 2 3 |
$ cat train/1734219226.txt 1 0.637242 0.526384 0.053579 0.094291 |
l’index de la classe d’objet (0->carré route, 1->carré vert)
la position en X du centre de l’objet
la position en Y du centre de l’objet
la largeur de l’objet
la hauteur de l’objet
Les coordonnées sont normalisées de 0 à 1 sur la largeur et la hauteur de l’image.
Augmentation du nombre d’image
Nous avons donc, pour l’ensemble de nos objets :
- 150 photos d’entraînement,
- 30 photos de validation,
- 30 photos de test,
- les photos sont au format .jpg et d’une dimension de 4608×2592 pixels,
- chaque photo est accompagné de son fichier label au format .txt
Il maintenant nécessaire de redimensionner les photos au format 640×640 pixels (pour YOLOv8),
de plus, il est intéressant d’augmenter artificiellement le nombre de photos !!
En effet l’entraînement de l’IA sur un plus grand nombre de photos permettra d’obtenir de meilleurs résultats
Plusieurs solutions permettent d’augmenter le nombre de photos :
- recadrer l’image par rapport à l’objet en positionnant l’objet plus ou moins sur la droite ou plus ou moins sur la gauche
–> cette opération permet de passer d’un format de 4608×2592 pixels à un format carré de 640×640 pixels - réaliser une ou plusieurs rotation d’image
- ajouter artificiellement du bruit ( des points blancs ou noirs )
- réaliser plusieurs itérations par image source
J’ai développé un script Python pour réaliser cela :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
cd RPI5_AI_Hailo_tests/Scripts/ python3 -m venv --system-site-packages venv source venv/bin/activate pip install -r requirements.txt cd bin cat dataset_HD_to_640x640.conf { "REP_IN" : "../../Dataset/Fred_Dataset/images_HD_2", "REP_OUT" : "/home/pi/My_Dataset/", "IMG_FILE_EXT" : ".jpg", "LABEL_FILE_EXT" : ".txt", "Nb_Iteration_par_image" : 15, "Add_Noise" : 1, "Retournement" : 3 } |
Le fichier de configuration défini les répertoires source et destination, le nombre de bruit, le nombre de retournement d’image
Le script se chargera également de recalculer la nouvelle position, en x et y, de l’objet et ses dimensions afin de produire un nouveau fichier label.
Le répertoire cible (REP_OUT) peut ne pas exister, le script se chargera de créer toute l’arborescence de répertoires.
Go !!!
|
1 |
python dataset_HD_to_640x640.py |
Puisque nous avons réalisé 15 itérations, pour lesquels nous avons une version avec et une version sans bruit, et nous avons réalisé 3 retournements en plus de la position de départ … notre Dataset est maintenant plus volumineux :
- 150 * 15 * 2 * 4 –> 18000 photos le répertoire « train »
- 30 * 15 * 2 * 4 –> 3600 photos dans le répertoire « valid »
- 30 * 15 * 2 * 4 –> 3600 photos dans le répertoire « test »
ce qui donne un total de 25200 photos accompagnées de leurs annotations !
en effet :
|
1 2 3 |
find /home/pi/My_Dataset -name *jpg | wc -l 25200 |
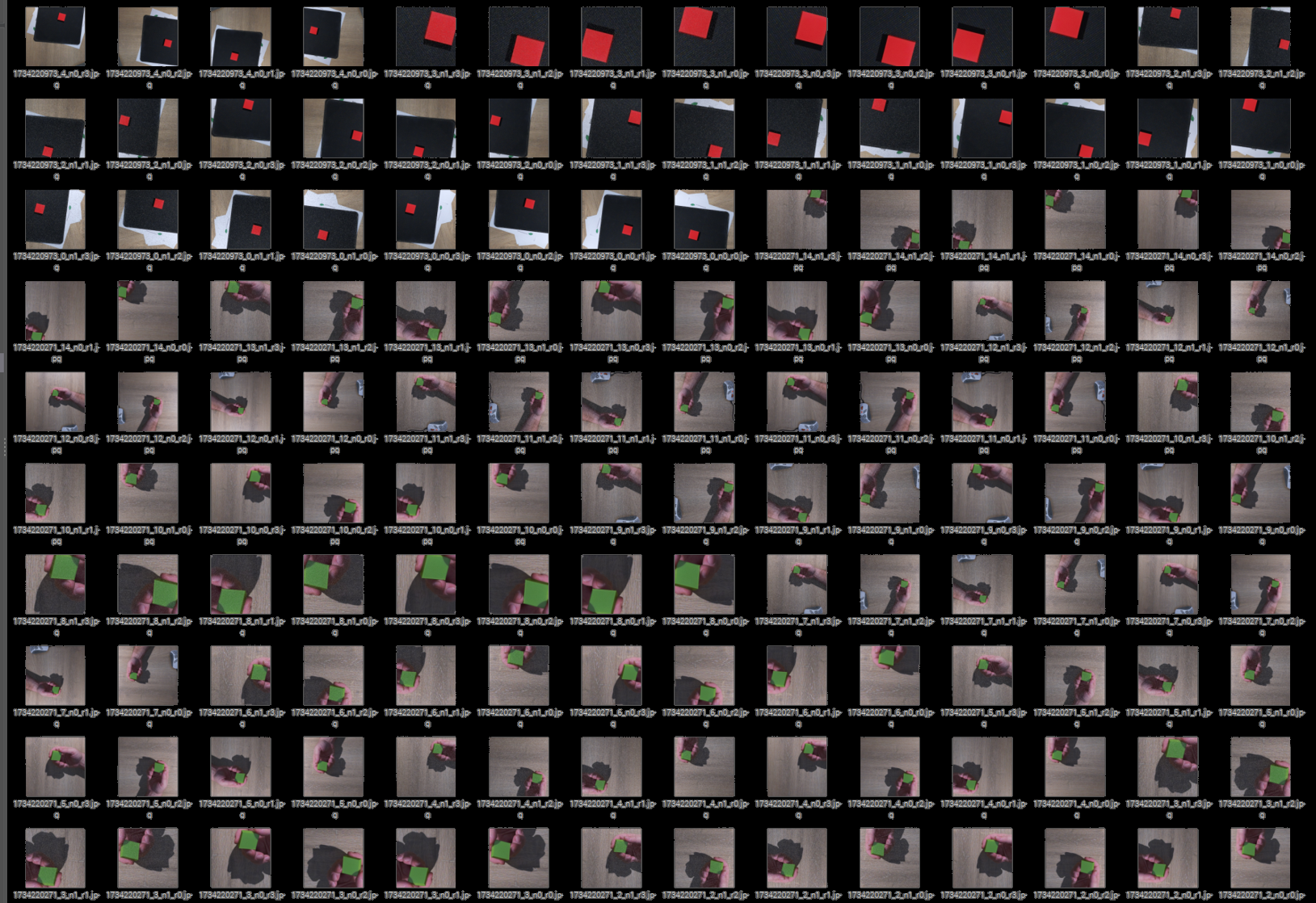
Notre Dataset est prêt à être utilisé pour l’apprentissage !!!
… mais il est également possible de créer son jeu de données en ligue, dans le cloud
Création du Dataset sur Roboflow
Une autre solution pour réaliser son dataset et l’annotation de ses images, est d’utiliser un outil en ligne.
Roboflow ( https://roboflow.com/ ) est une plateforme tout-en-un qui facilite la gestion, l’annotation, l’augmentation et l’exportation de datasets pour l’entraînement de modèles de vision par ordinateur. Elle est particulièrement utile pour des modèles comme YOLOv8, Faster R-CNN, SSD, et d’autres.
On peut identifier plusieurs fonctionnalités très intéressantes :
- Annotation d’images : Interface web collaborative pour annoter rapidement les objets.
- Augmentation des données : Ajout automatique de variations (rotation, flou, contraste, etc.) pour améliorer la robustesse du modèle.
- Conversion de formats : Compatible avec YOLO, COCO, Pascal VOC, et d’autres standards.
- Hébergement & API : Stocke et gère les datasets, avec accès via API pour automatiser les workflows.
- Entraînement et déploiement : Intégration avec des frameworks d’IA (PyTorch, TensorFlow) et déploiement dans le cloud ou en edge computing.
Une dès première fonctionnalité très intéressante que j’ai exploitée :
- Roboflow permet d’extraire une série de photos depuis une vidéo !!!
Mon nouveau Dataset :
Cette fois ci, pour ce nouveau Dataset, j’ai choisi un nouvel énoncé de départ :
- un Dataset avec 4 classes : round, square, triangle, hexagon
- les 4 objets sont de couleur identique ( vert )
- les images sont extraites de 4 vidéos distinctes
- chaque vidéo dure exactement de 20 secondes
Pour réaliser les vidéos, c’est très simple ! il suffit d’utiliser la caméra du Raspberry PI !
Avec la commande suivante :
|
1 |
rpicam-vid --camera 0 -t20000 --autofocus-range normal --autofocus-speed fast -o square.mp4 |
Nous pouvons bien évidemment ajuster les paramètres d’autofocus et autres …
Ces vidéos de départ sont dans le répertoire : Dataset/210125_4_shapes_TEST.sources du dépôt Git :
|
1 2 3 4 5 6 |
ls -al Dataset/210125_4_shapes_TEST.sources/ -rw-rw-r-- 1 fredj21 fredj21 4881188 janv. 29 13:37 hexagon.mp4 -rw-rw-r-- 1 fredj21 fredj21 4985373 janv. 29 13:37 round.mp4 -rw-rw-r-- 1 fredj21 fredj21 4848499 janv. 29 13:37 square.mp4 -rw-rw-r-- 1 fredj21 fredj21 5261945 janv. 29 13:37 triange.mp4 |
Direction donc –> http://www.roboflow.com/
Après s’être identifié,
on crée un nouveau projet public de type « Object Detection » avec le nom des différentes classes
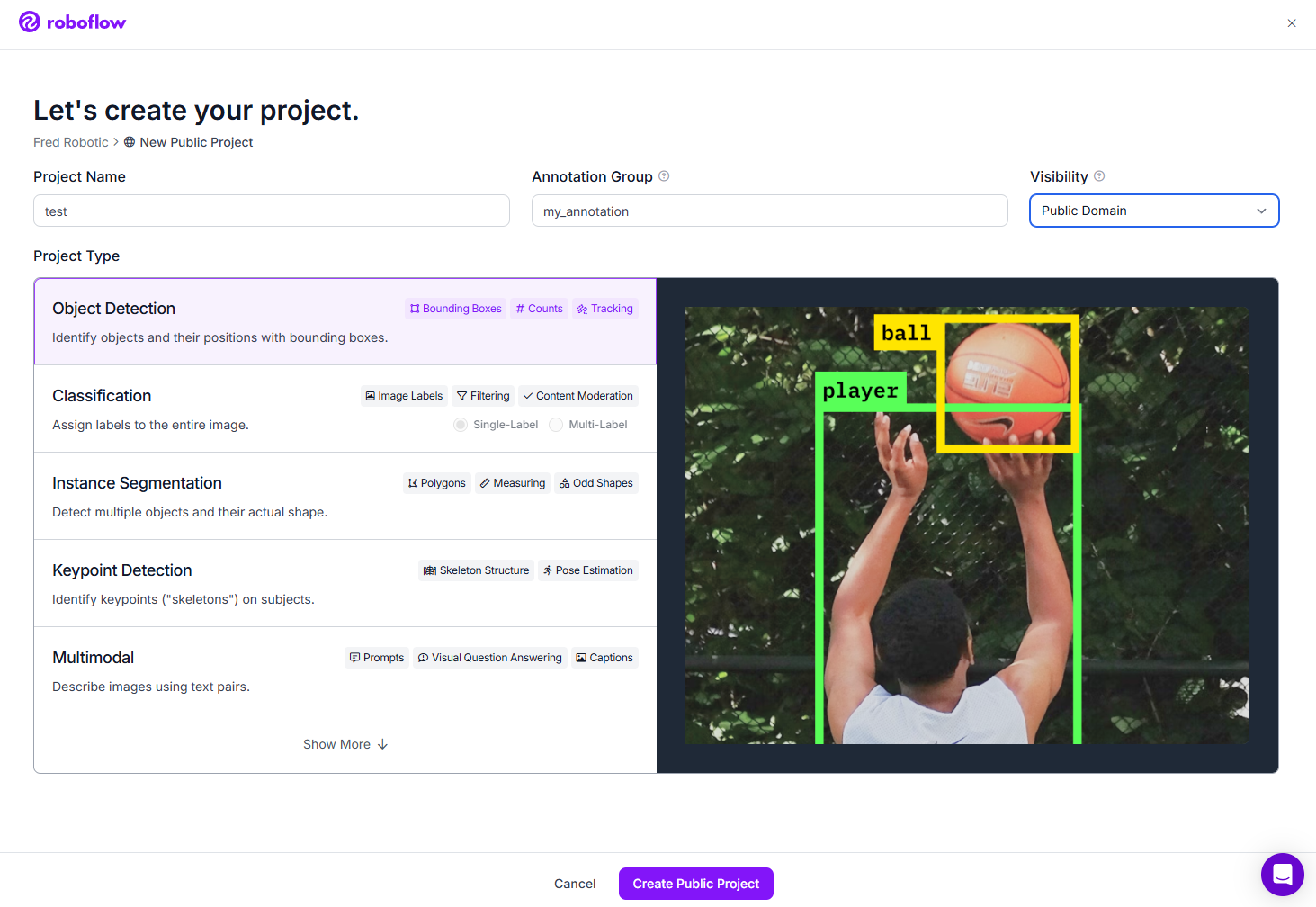
Maintenant, dans la section « Upload Data », nous importons chaque vidéo, l’une après l’autre
avec une fréquence d’échantillonnage de 5 images par seconde (choix arbitraire à adapter à ses besoins)
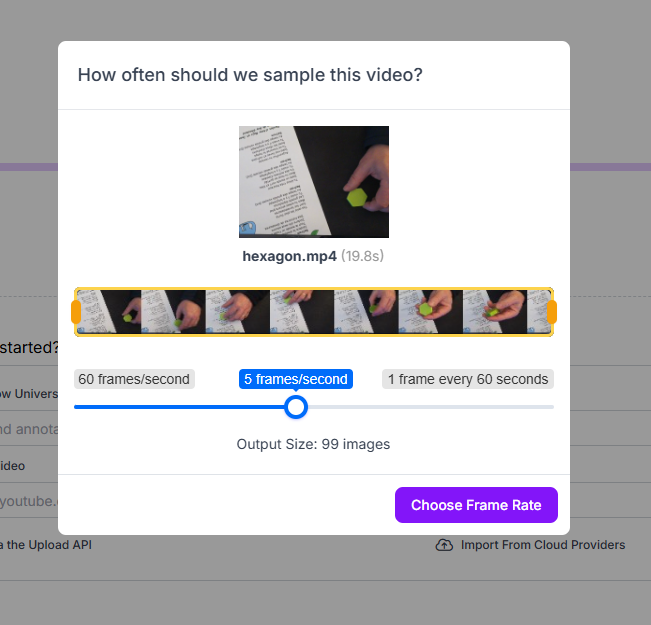 |
 |
On crée des tâches de type « Manual Labeling », que l’on assigne à soi même.
En effet, la plateforme est collaborative, et permet d’assigner des taches à différentes personnes
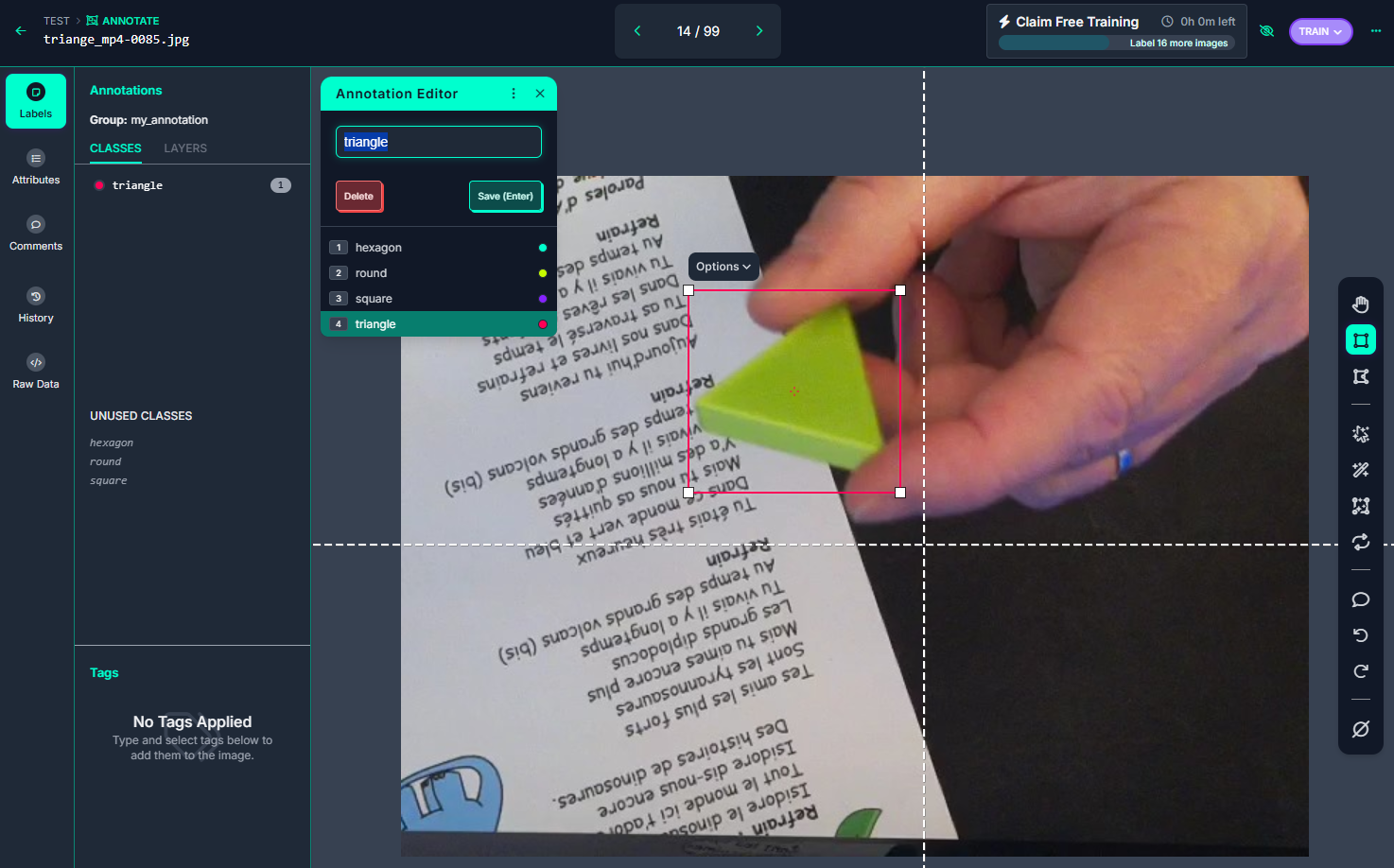
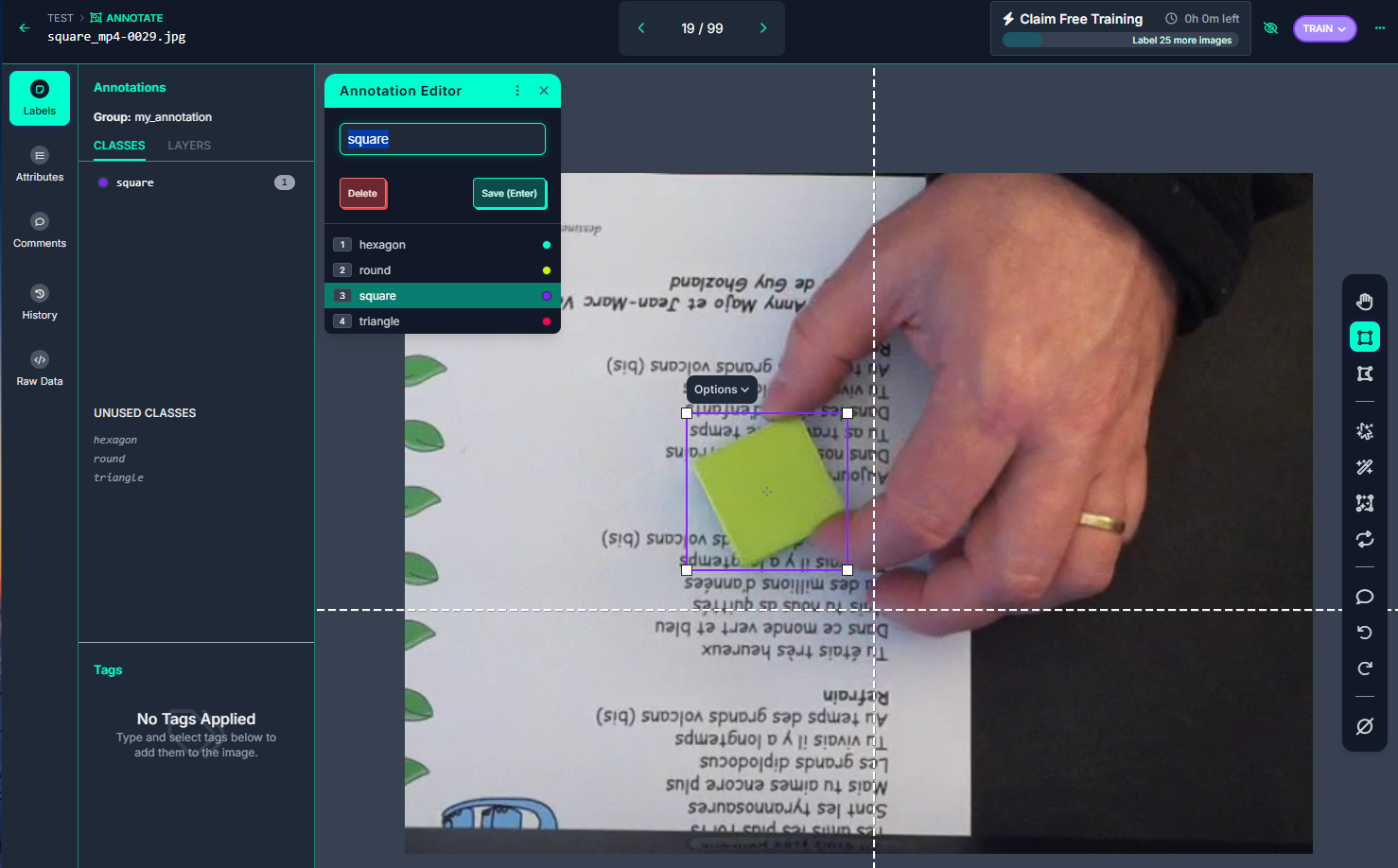
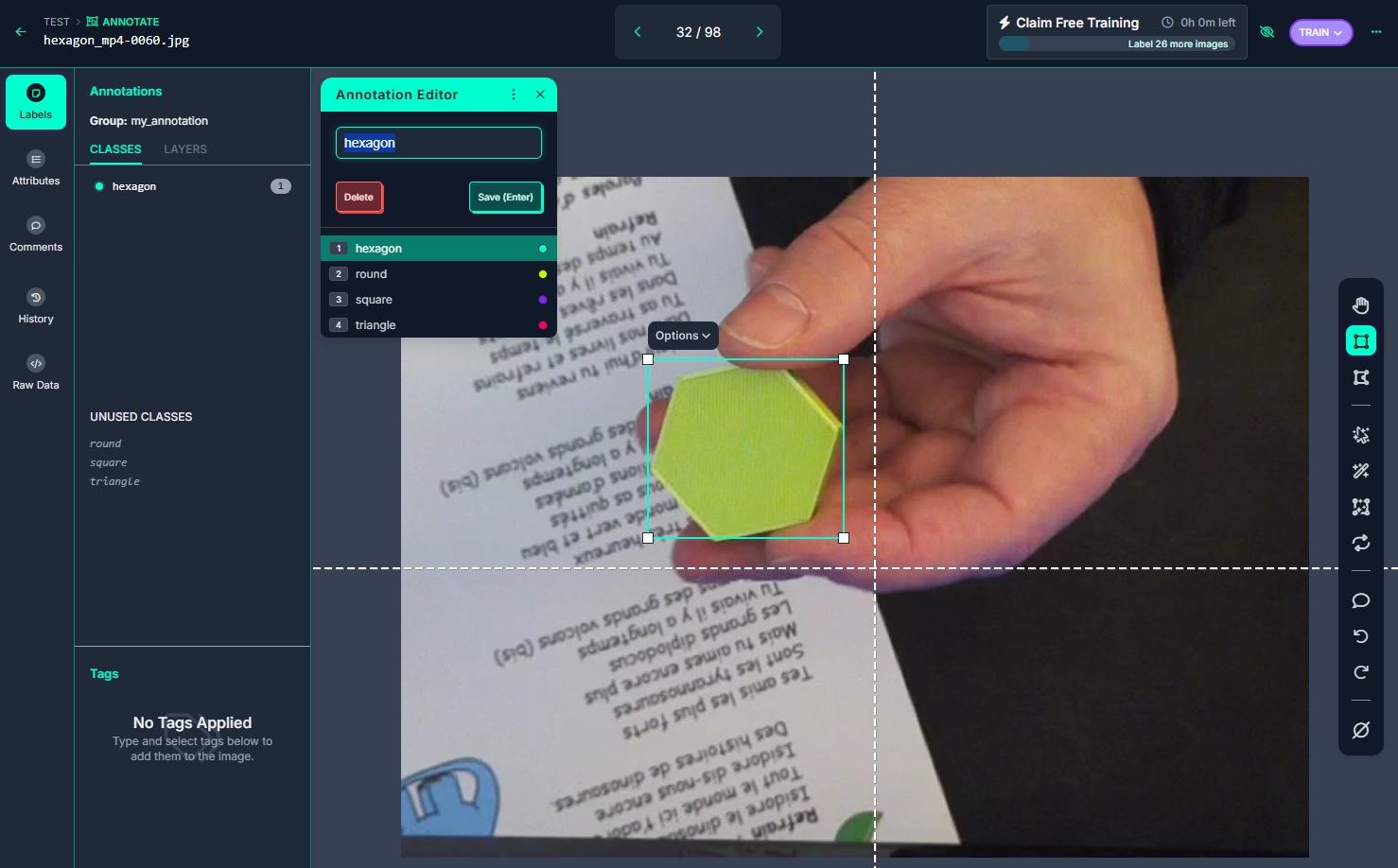
Dans la section « Annotate », nous pouvons visualiser les différentes taches restants, la personne en charge de cette tâche, le taux de réalisation
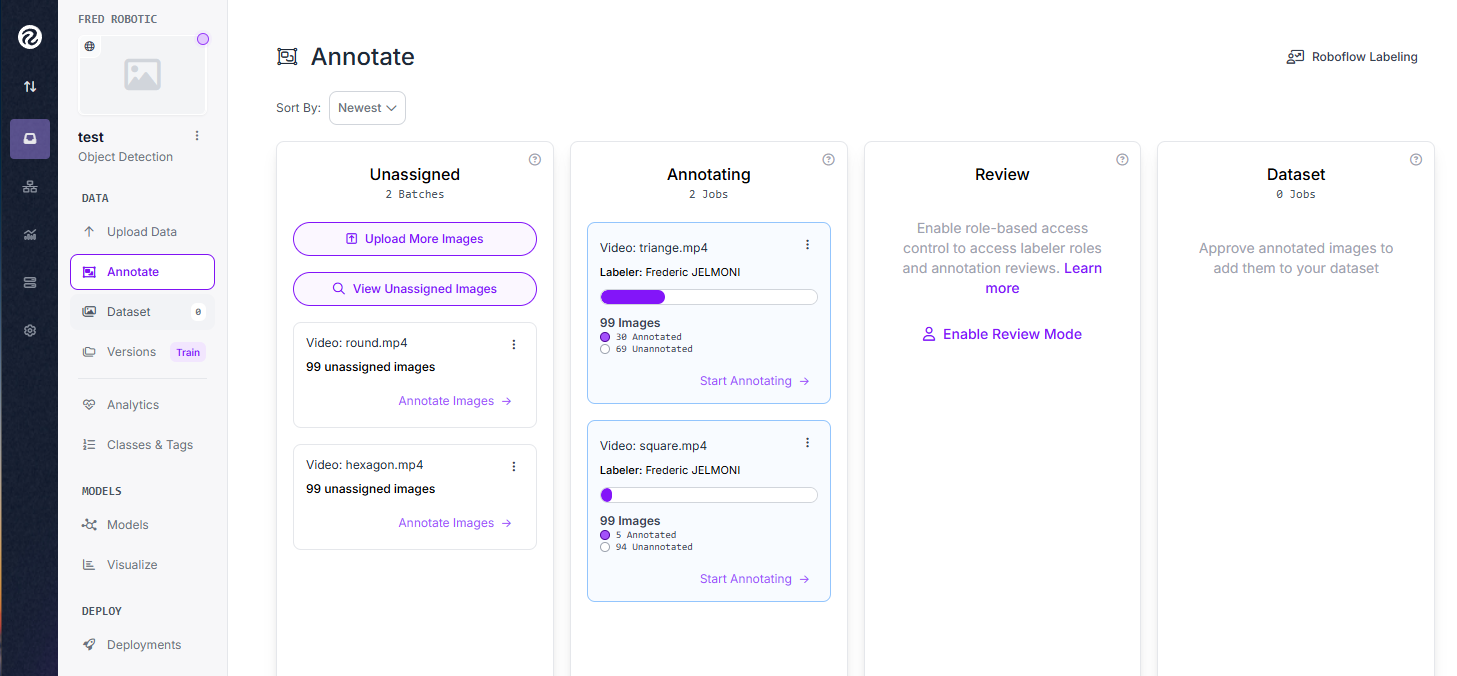
Pas de difficulté lors du labeling, il faut juste veiller à sélectionner la bonne classe …. et avoir un peu de patience !!!
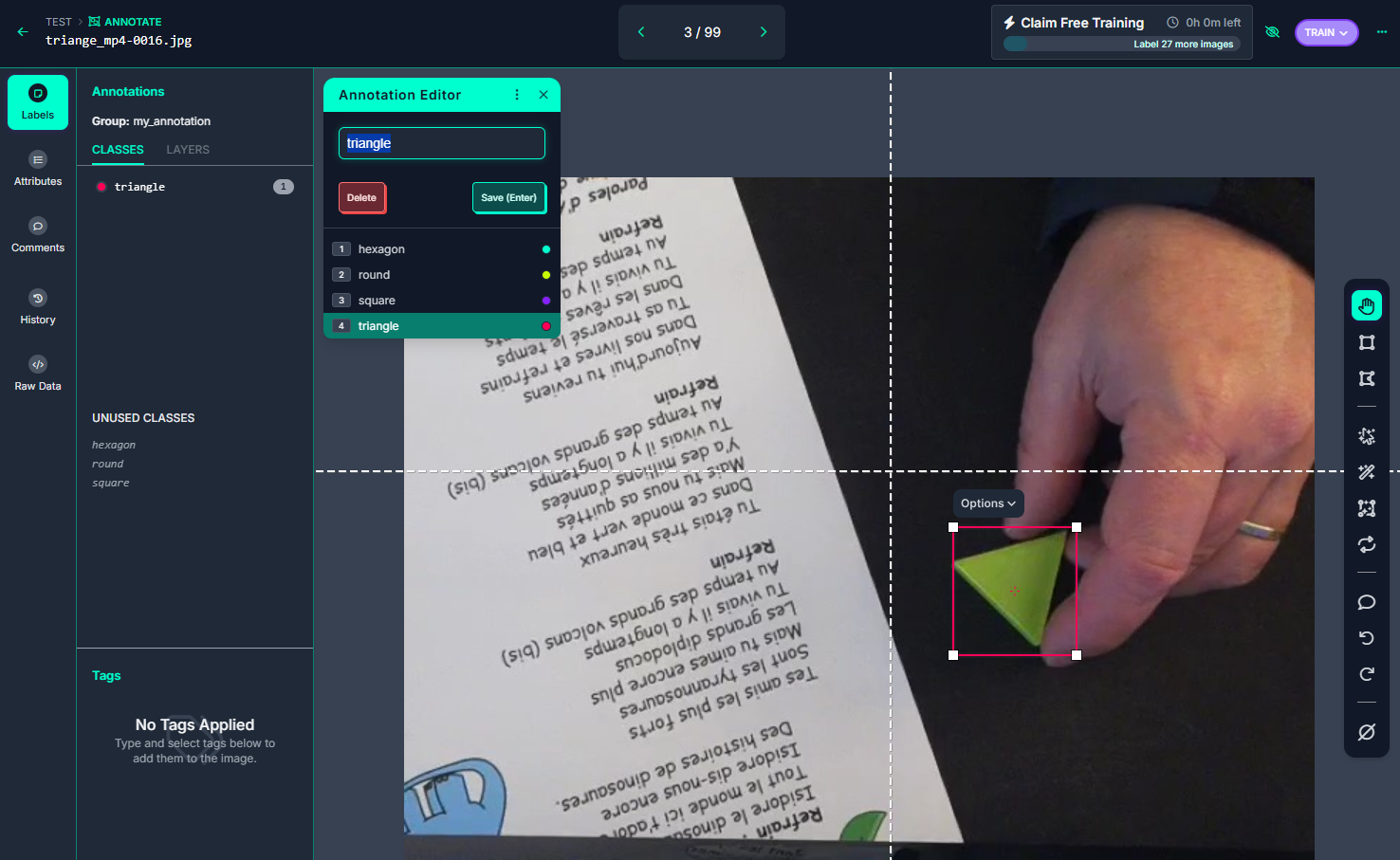 |
 |
 |
 |
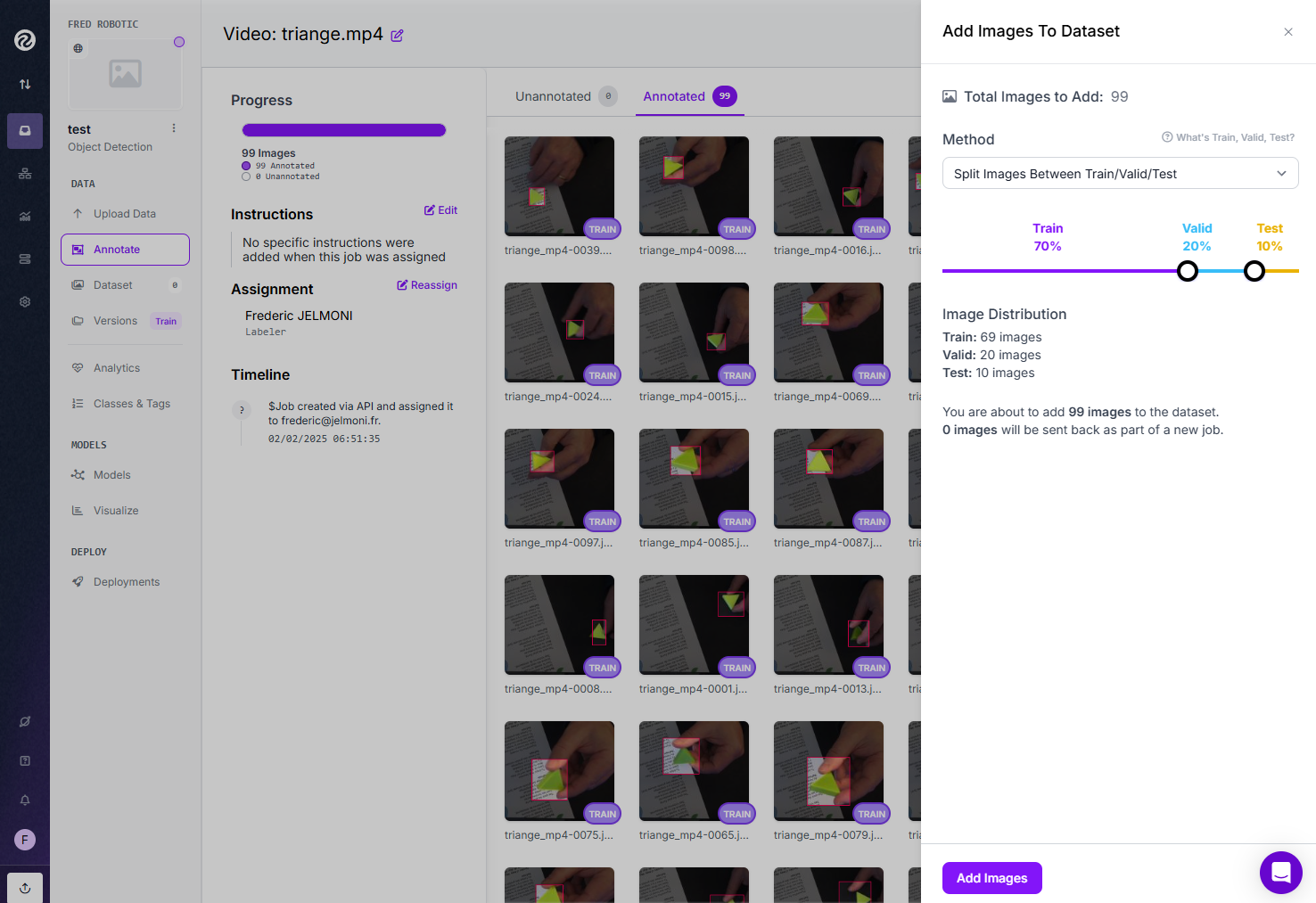
Après avoir annoté l’ensemble des images, nous allons ajouter ces images à notre Dataset en utilisant la méthode « Split Images Between Train/Valid/Test » qui permettra de répartir aléatoirement nos photos pour les besoins de training, validation et test.
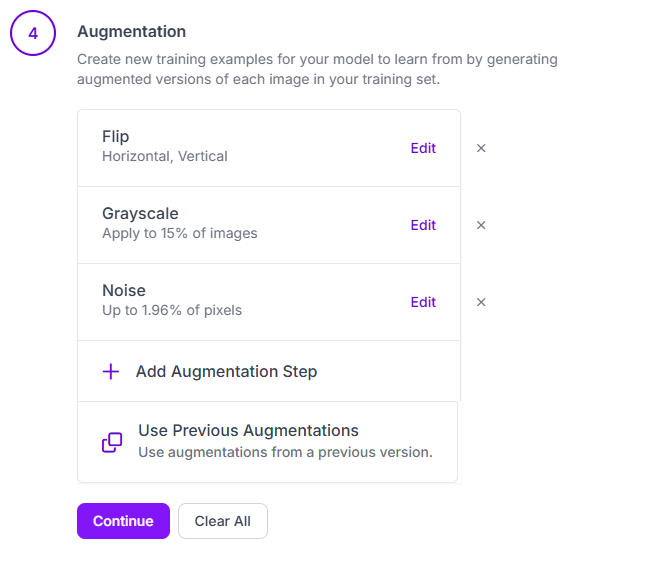
Enfin, il nous reste à générer une nouvelle version de notre Dataset en appliquant des opérations de rotation, ajout de bruit, passage de certaines photos en niveau de gris, ….
Le but étant, ici, d’augmenter artificiellement le nombre de photos de notre Dataset
Dans la section « Dataset » –> « Generate Version »
Pour résumer cette création de son jeu de données sur Roboflow:
Nous sommes parti sur la base de :
- 4 vidéos de 20 secondes
- un échantillonnage de 5 images par seconde
- ce qui donne : 99 images par classe
Après l »opération de « split », nous obtenons :
- 70 % Train –> 69 images
- 20 % Validation –> 20 images
- 10 % Test –> 10 images
Un total donc, pour l’ensemble des classes de :
- 276 image de training
- 80 images de Validation
- 40 image de Test
Ensuite, la création d’une version du Dataset ( augmentation du nombre d’image)
- rotation horizontal et vertical
- gris 15% des images
- bruit 1.96%
Lors de cet augmentation, nous sommes limité, dans la version gratuite de Roboflow, à 1500 images !
Nous avons donc maintenant :
- 1380 image de training
- 80 images de Validation
- 40 image de Test
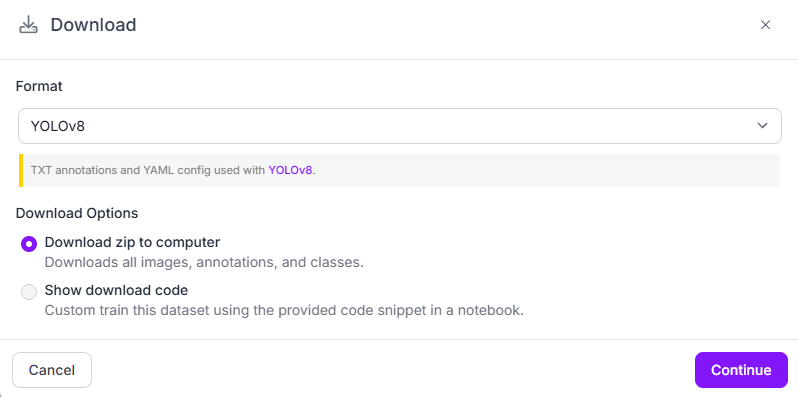
Téléchargement du jeu de données
Nous pouvons maintenant télécharger notre Dataset dans de nombreux formats
–> particulièrement au format YOLOv8 pour la suite de notre projet !
l’ensemble des fichiers se trouve dans le répertoire : Dataset/210125_4_shapes_TEST.v2i.yolov8/ du dépôt Git :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
ls -l Dataset/210125_4_shapes_TEST.v2i.yolov8 -rw-rw-r-- 1 fredj21 fredj21 299 févr. 2 08:08 data.yaml -rw-rw-r-- 1 fredj21 fredj21 150 févr. 2 08:08 README.dataset.txt -rw-rw-r-- 1 fredj21 fredj21 1190 févr. 2 08:08 README.roboflow.txt drwxrwxr-x 4 fredj21 fredj21 4096 févr. 2 08:08 test drwxrwxr-x 4 fredj21 fredj21 4096 févr. 2 08:08 train drwxrwxr-x 4 fredj21 fredj21 4096 févr. 2 08:08 valid tree Dataset/210125_4_shapes_TEST.v2i.yolov8 -d Dataset/210125_4_shapes_TEST.v2i.yolov8 ├── test │ ├── images │ └── labels ├── train │ ├── images │ └── labels └── valid ├── images └── labels |
Prêt à coder !!!
Robotflow propose également, dans la section « Download », plusieurs méthodes d’accès au Dataset.
et plus particulièrement une librairie Python pour automatiser le téléchargement de son Dataset
|
1 2 3 4 5 6 7 8 9 |
pip install roboflow python from roboflow import Roboflow rf = Roboflow(api_key="xxxxxxxxxxxxxxxxxxx") project = rf.workspace("fred-robotic").project("210125_4_shapes_test") version = project.version(2) dataset = version.download("yolov8") |
Prêt à entrainer notre modèle !!!
Ce sera l’objet du prochain article que vous pouvez lire ici.
Conclusion de ce premier article
Frédéric remercie particulièrement Kubii pour la fourniture du matériel qui a servi à réaliser toutes ces expériences, et en particulier pour le module d’Intelligence artificielle Hailo, indispensable dans ce développement.
Les articles de cette trilogie :
Sources
Vous pouvez retrouver les images et vidéos sources, ainsi que certains résultats des test et quelques scripts sur le dépôt GitHub suivant :
https://github.com/FredJ21/RPI5_AI_Hailo_tests
Ping : Créer et Entraîner son propre IA pour le module AI HAILO du Raspberry PI 5 [Partie 1]
Ping : JELMONI alias Fred Robotic) & (et vice-Président) - Framboise 314, le Raspberry Pi à la sauce française....
Bonjour,
Je viens de terminer la lecture de la première partie et je tiens à vous remercier pour la qualité de la documentation.
Elle est claire, bien structurée et extrêmement utile.
Je suis particulièrement impressionné par les détails et la précision des informations fournies.
Un grand merci à vous deux pour votre travail remarquable et votre engagement. Votre expertise transparaissent dans chaque page, ce qui facilite grandement la compréhension et notre progression.
J’ai hâte de lire les parties suivantes et de continuer à apprendre
Cordialement,
merci 🙂
Merci pour ton retour !